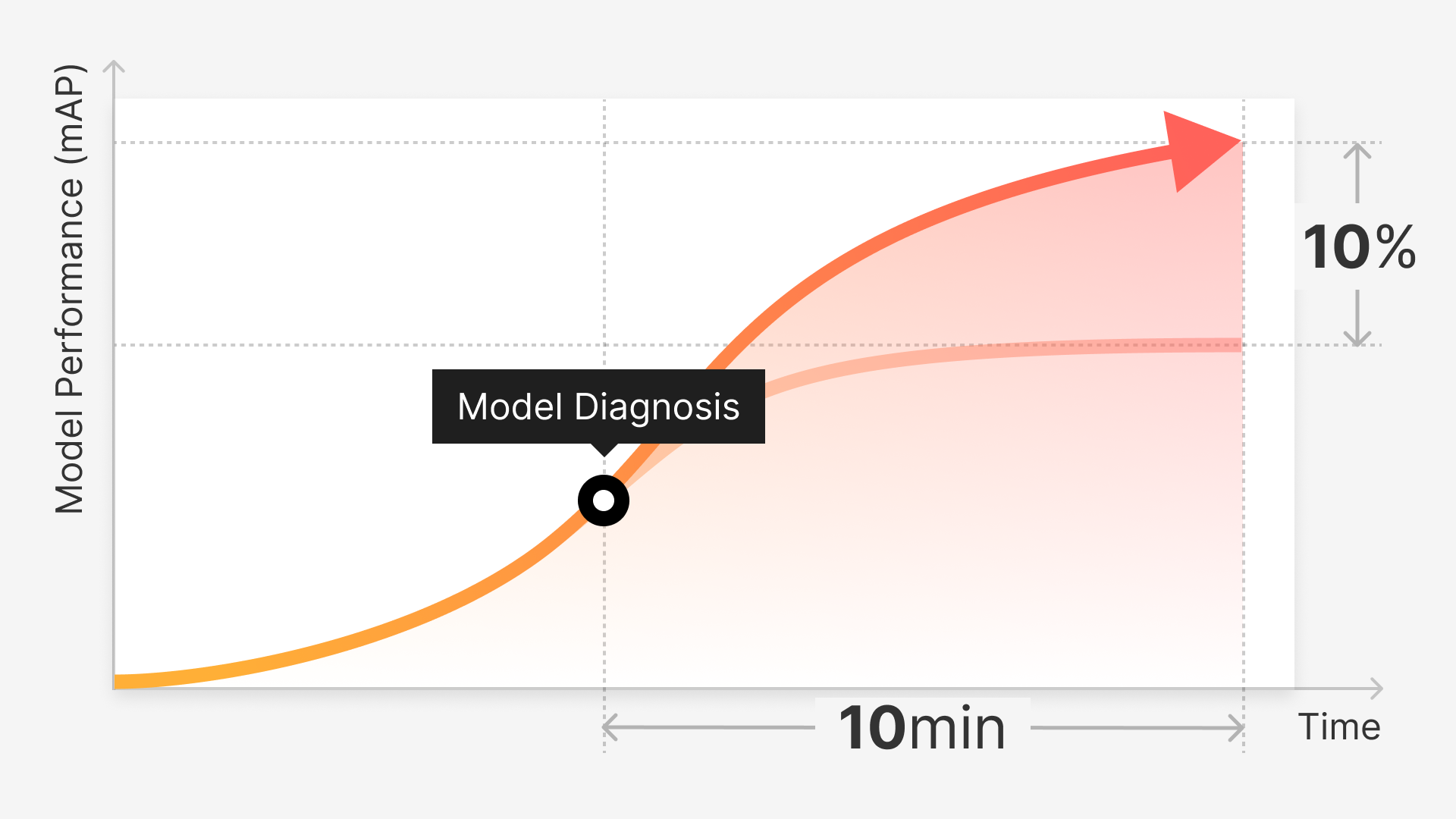
In this series of tech blog posts, we would like to walk you through one of our main AI technologies called Auto-Label — how we are approaching it, updates on our progress, and its impact on our end users. We believe breakthroughs in Auto-Label technology have the potential to revolutionize how we build AI systems in the future.
Part 1 is an overview of our Auto-Label framework and our key R&D milestones for advancing this technology. Let’s first start by going over how a fully manual labeling workflow looks like.
I. Manual Data Labeling
The most common and simplest approach to data labeling is, of course, a fully manual one. A human user is presented with a series of raw, unlabeled data (such as images or videos), and is tasked with labeling it according to a set of rules. This simple workflow is illustrated below.
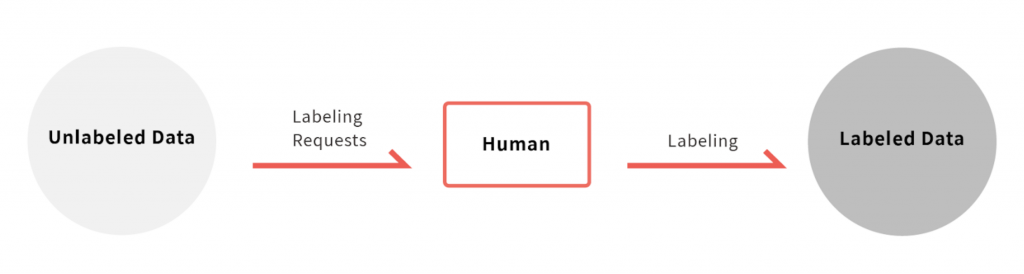
Basic data labeling workflow
For example, when processing image data, the most common types of annotations are classification tags, bounding boxes, polygon segmentation, and keypoints.
Classification tags, which are the easiest and cheapest annotation, may take as little as a few seconds whereas fine-grained polygon segmentation could take a few minutes per each instance of objects. In order to calculate the impact of AI automation on data labeling times, let’s assume that it takes a user 10 seconds to draw a bounding box around an object, and select the object class from a given list. This is an observable assumption backed by our own empirical evidence.
In this case, a typical dataset with 100,000 images and 5 objects per image, it would take around 1,500 man-hours to label and this would be equivalent to spending around ~$10K just for data labeling.
Adding a layer of quality control in order to manually verify each piece of labeled data also adds time to delivery. It would take a trained user about one second to check-off each bounding box annotation, thereby increasing the labeling costs by about 10%. Some workflows may choose to adopt consensus-based quality control. This is when multiple users annotate the same piece of data and the results are consolidated/compared for quality control. With consensus-based workflows, the amount of time and money spent is proportional to the number of users that work on overlapping tasks for consensus. Simply put, if you had three users label the same image three times, you would have to pay for all 3 annotations.
All this is to emphasize that, the two most expensive steps in data labeling are 1) the data labeling itself, and 2) reviewing and verifying it for quality control. And therefore, the utmost purpose of Auto-Label technology is reducing the time for both data labeling and verification.
Thankfully, with advancements in AI and machine learning, Auto-Label technology has come a long way. However, not all Auto-Label technologies are created equally, and, in many instances, naive attempts to use AI end up requiring more human input for correcting errors induced by the AI. Therefore, one has to be extremely cognizant of how the selected AI impacts the overall data workstream.
We will now dive into what Superb AI’s Auto-Label exactly is, the purpose behind this technology, and the advancements that Superb AI is making in this field.
II . Automatic Data Labeling
Let’s first look at how we can reduce data labeling time. When we build an Auto-Label system, the data labeling workflow is as follows:
Auto-Label AI labels raw, unlabeled data.
A human user verifies the label.
In the case in which data is correctly labeled, it is added to the pool of labeled training data.
In the case in which data is mislabeled, the data is considered valuable for re-training the Auto-label AI and a human labeler will proceed to correct the errors. Once the data is labeled at a satisfactory level, it is then used to re-train the Auto-Label AI and subsequently added to the pool of labeled training data.
ML teams use the compiled labeled training data to train various models.
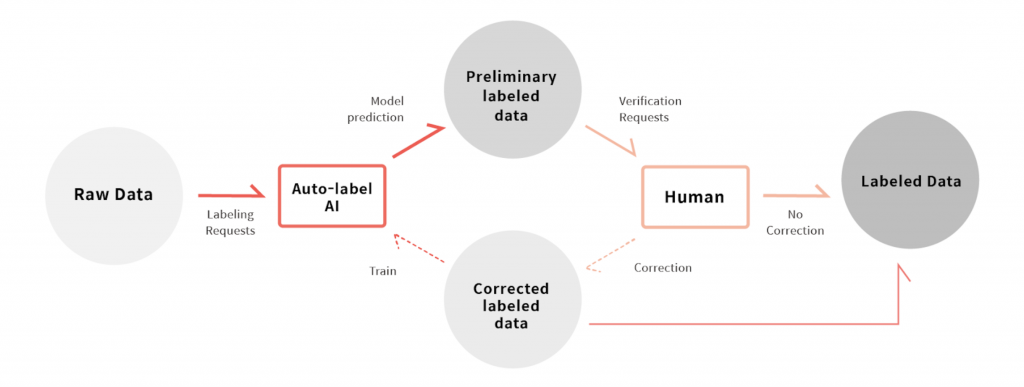
Using Auto-Label to Reduce Data Labeling Time
Assuming that a decently trained AI model is available, the output (the model predictions) should be fairly accurate in most cases and only the edge-cases would need human correction.
Even for applications like self-driving, which requires massive amounts of data to train extremely accurate AI models, most data points only have marginal value in improving the model performance — it’s the rare, edge-cases in the long-tail distribution of data (such as scenes of car accidents) that helps improve model performance.
As such, for a company to develop the most accurate and the highest performing AI models, it’s not the mere size of the dataset that matters but it’s rather a game of who can find and gather the most edge-cases to train their models with. Therefore, it’s paramount that a company weed out the trivial cases of data that AI models are already well-trained on, and spend the time and resources wisely on labeling (or really, correcting already labeled) high-value data.
2-1) Impact of Automating Data Labeling
We demonstrate below how using trained AI models to label data can impact the amount of time that goes into data labeling.
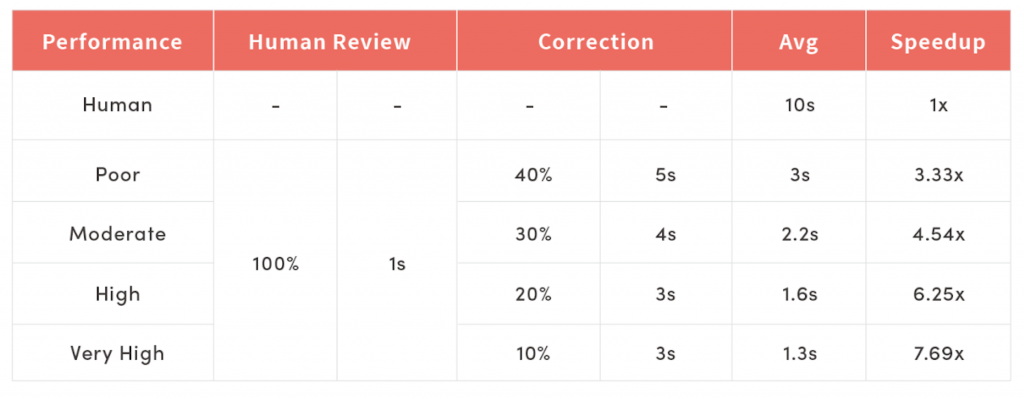
Impact of auto-label on data labeling efficiency
As mentioned above, a typical bounding box annotation takes 10 seconds to label, and 1 second to verify. Also, it takes between 2~10 seconds to correct labeling errors, depending on the type of error, and it averages out to 3~5 seconds (more on this below). And, depending on what percentage of the bounding box annotations need human correction, we’ll describe each AI model performance as “poor”, “moderate”, “high” and “very high”.
According to the experiment, even when the AI model performed “poorly” (a human user had to correct 40% of the AI model predictions), we’ve achieved over 3x improvement in labeling speed. If we improved the performance to “high” (20% of predictions need correction), we could achieve over 6x speedup and save over 80% of the time and data labeling costs. It’s worth noting that this level of AI model performance is a very reasonable target for typical situations.
2-2) Types of Errors and Corrections
Some readers may be wondering, why does the time for label correction decrease from 5 seconds to 3 seconds as the model performance increases? To address this, we first need to look at the four types of AI model prediction errors, or equivalently the types of human label corrections required for each case.
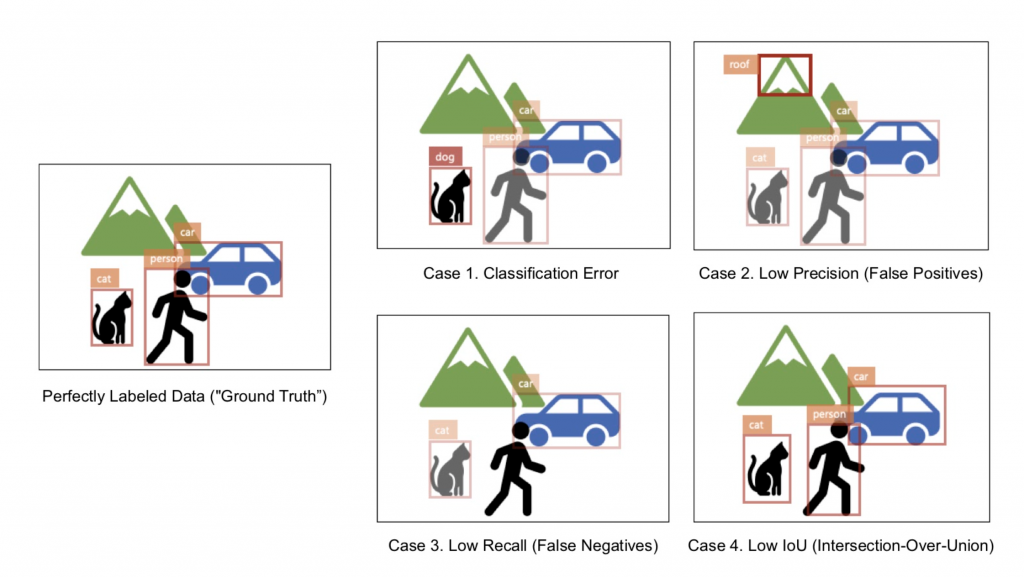
AI model prediction errors
**Case 1. Classification Error:
**This is when the object class is mis-selected. In this illustration above, the cat is misclassified as a dog. In this case, a human user must change the object class from a list.
**Case 2. Low Precision (False Positives):
**A model has low precision when it has many false positive annotations (i.e. mistakenly outputs bounding boxes when it should not). In the illustration above, a “roof” bounding box is drawn where a mountain is. (You could argue this is a classification error if the mountain was within your class set). In this case, a human user must delete the given bounding box.
**Case 3. Low Recall (False Negatives):
**A model has low recall when it has many false negatives (i.e. failing to detect and output bounding boxes when it should). A model should have detected and output a “person” bounding box but it failed to do so. In this case, a human user must draw a new bounding box and select its class.
Case 4. Low IoU (Intersection-over-Union**):
**The last type of error is low IoU (i.e. the bounding boxes are not tightly fitted to the objects present in the image). In this case, a human user must adjust the bounding box coordinates accordingly.
As you can tell, the types of errors that take the most amount of time to correct are Case 3 (Low Recall) and Case 4 (Low IoU). It takes a user about 10 seconds on average to annotate a bounding box completely from scratch for Case 3, and it takes about the same amount of time to re-adjust the bounding box coordinates to fit around an object for Case 4. In contrast, it only takes about 2 seconds to change an object class (Case 1) or delete a wrong bounding box (Case 2).
Based on such reasoning, our research efforts focus on optimizing the Auto-Label AI’s recall and IoU measures, among others, so that we can:
Reduce the number of cases that require human correction, and
Reduce the ratio of error cases that require the most time to correct, and therefore reduce the average amount of time per correction.
III. More Advanced Auto-Label Methods
So far, we’ve looked at how we can automate data labeling using Auto-Label AI and achieve more than 6x faster labeling speeds. In this section, we’d like to introduce you to the two main directions we’re advancing our Auto-Label AI technology.
3-1) Reducing Human Verification Time Using Uncertainty Estimation
As aforementioned, Auto-Label can not only be used to automate data labeling but also for automating labeling verification. At Superb AI, we’ve developed a proprietary “uncertainty estimation” technique with which an Auto-Label AI can measure how confident it is with its own labeling predictions.
In other words, our Auto-Label AI outputs annotations (i.e. bounding boxes and the corresponding object class) and simultaneously outputs how confident it is with each annotation. Therefore, it requests human verification only in cases the AI is uncertain about, and as a result, reduces the amount of work that goes into human verification of labels.
We illustrate such as workflow below. What was previously categorized as “Auto-Labeled Data” is now split between “certain” and “uncertain” based on the model’s uncertainty output. A user can assume that the annotations Auto-Label AI marked as “certain” does not need any human verification, and only focus on verifying the small number of “uncertain” cases. Human users are tasked with verifying fewer numbers of data and thus the cost to label a dataset is reduced.
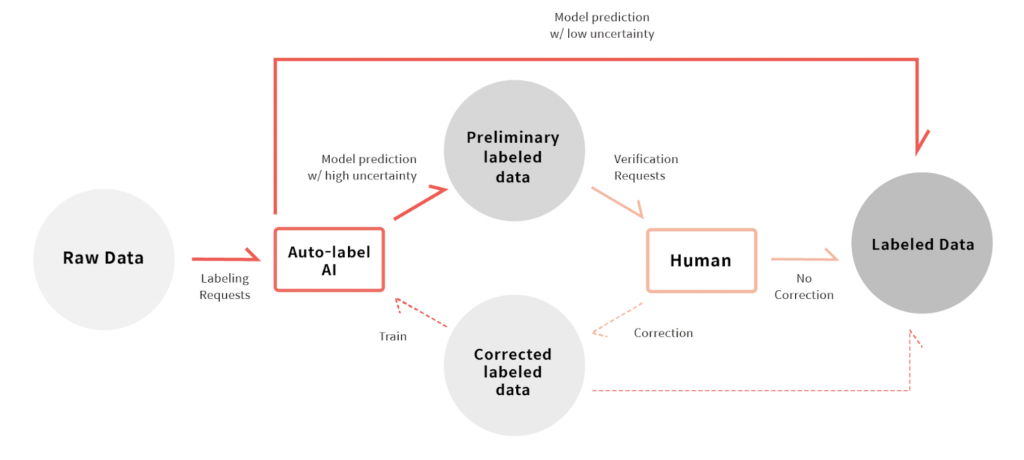
Auto-label workflow
We show how the Uncertainty Estimation (U.E.) technique impacts data labeling efficiency below.
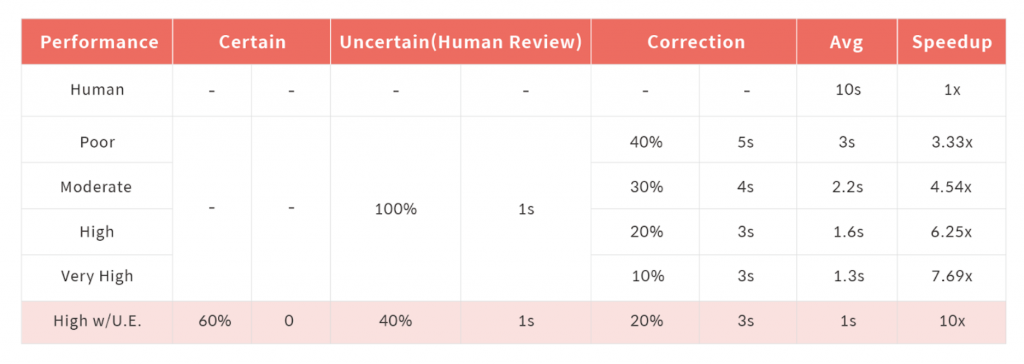
impact of auto-label on data labeling efficiency
We applied the Uncertainty Estimation technique to the AI model with “High” accuracy. Although a human user had to review 100% of the data with plain Auto-Label AI, Uncertain Estimation marked 60% of the data as “certain” and the user was only tasked with reviewing 40% of the data. (And, about half of the “uncertain” cases, or 20% of the total, ended up requiring human correction as was the case without U.E.)
In this case, we could achieve a 10x speed boost, which was a higher gain than using an Auto-Label AI model with “Very High” performance.
Likewise, using Uncertainty Estimation to reduce human verification is one of the main portions of Superb AI’s Auto-Label AI technology. We’re currently developing this using the Bayesian Active Learning (BaaL) framework, and we’ll take a deeper dive into this on our next post in this series.
3-2) Adapting Auto-Label AI to New Tasks with Few Data (a.k.a. Remedying Cold-Start Problem)
Another way in which we are advancing our Auto-Label AI is by adapting pre-existing Auto-Label AI models on new tasks using a small number of data.
Besides the common task of annotating object classes such as “person” or “car” with bounding boxes, there are myriads of different object classes, data domains, and labeling tasks. Generally, training an Auto-Label AI on a new set of object classes, data domain or labeling task requires a significantly large amount of labeled data, and until then, one must rely on manual data annotation process. For example, if you are given images of product parts at factory production lines, there is absolutely zero chance that a pre-trained Auto-Label AI can detect these objects and one must first manually annotate a significant number of them before fine-tuning the model on this new data. This is called the “Cold-Start Problem”.
In order to remedy this problem and help our users benefit from our Auto-Label AI even on very niche data, we apply techniques such as Transfer Learning and enable our AI model to quickly fine-tune on a small number of data. We’ll also discuss this in-depth on a separate post soon.
IV. Coming Up Next…
With that, we’ve overviewed Superb AI’s key AI technology called Auto-Label, its purpose, and how we’re advancing it. In the next few posts listed below, we’ll showcase some of the specific AI techniques we have developed, how we have incorporated into the Suite, and how you can benefit from them.
Superb Tech Series: Auto-Label
Part 1. Introduction to Superb AI’s Auto-Label Tech (← You are here)
Part 2. Estimating Auto-Label Uncertainty for Active Learning
Part 3. Improving Auto-Label Accuracy with Class-Agnostic Refinement (Coming soon)
Part 4. Adapting Auto-Label AI to New Tasks with Few Data (Remedying the Cold-Start Problem) (Coming soon)