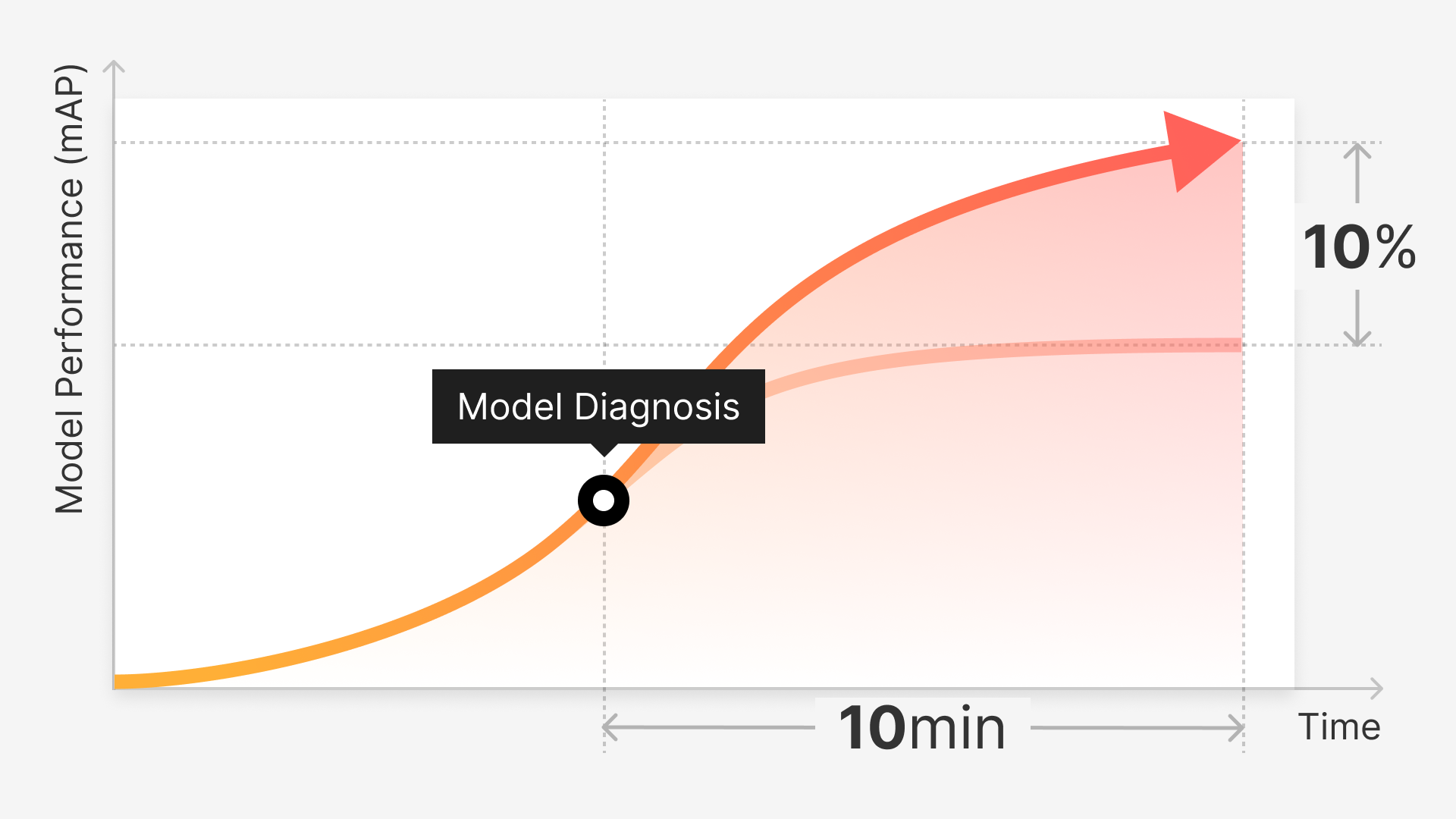
Progress in Computer Vision (CV) technology is transforming various industries by integrating unparalleled levels of automation and smart functionality. Yet, constructing accurate and unbiased CV models is often a complex process.
The secret to navigating these hurdles lies in the creation of balanced, high-quality datasets. In this context, Superb Curate has proven to be an outstanding resource for streamlining the process of data curation.
In this article, we will delve into the primary challenges associated with maintaining data balance and accuracy, and we'll show you how Superb Curate can effectively address these issues.
We Will Cover
Data imbalance and accuracy challenges
Simplifying manual data management
Key techniques for balanced curation
Employing Superb Curate’s curation workflow
Notable industry use cases
Data Balance and Accuracy Challenges
Building an effective CV model is not as simple as feeding the model a large amount of data. Data-related challenges in CV include class imbalance, scenario imbalance, data variability and noise. The struggle of data separation and relevance, systematic metadata collection during data acquisition, and the pitfalls of relying on intuition for data collection add further hurdles to the process.
One common misconception is that “more data is always better”, an approach that often leads to diminishing returns. Without an effective data curation process, the inclusion of irrelevant data can confuse the model, leading to lower accuracy. Moreover, relying solely on intuition or implementing random sampling often results in unrepresentative data, thereby affecting the model's performance.
1. Class and Scenario Imbalance
One common hurdle in CV is class imbalance. This occurs when the dataset used for training a model contains more instances of some classes than others. For example, a dataset may have an abundance of images of cars but very few of bicycles.
This leads to a model that is highly accurate at identifying cars but struggles to recognize bicycles. Scenario imbalance is another related issue, where certain situations or contexts are over-represented or under-represented, thus leading to skewed performance of the model across different real-world scenarios.
2. Data Variability and Noise
Data variability and noise present additional challenges. Variability refers to the differences or variations that can occur within a single class. For instance, the same object can appear differently based on the angle, lighting conditions, or occlusions. Noise, on the other hand, is the presence of irrelevant or misleading information in the data that can impede the model’s learning process.
3. The Struggle of Data Separation and Relevance
Ensuring data separation and relevance can also be an uphill battle. Training, validation, and test sets need to be distinct to prevent data leakage and overfitting. However, creating these sets manually is labor-intensive and prone to errors. Additionally, not all data is equally relevant or useful for a particular task. Identifying and focusing on the most pertinent data is a challenging but critical aspect of model training.
4. Systematic Metadata Collection During Data Acquisition
Systematic metadata collection during data acquisition is another concern. Metadata, such as the time of day an image was taken or the weather conditions, can provide valuable contextual information for a CV model. However, collecting this metadata in a systematic and standardized manner can be difficult, leading to inconsistencies and gaps in the dataset.
5. Perfect Random Sampling
The pitfalls of relying on intuition and the challenge of perfect random sampling can't be overlooked. Curating a balanced and representative dataset based on intuition alone is nearly impossible given the high dimensionality and complexity of visual data.
Similarly, creating a truly random sample from a population is a non-trivial task. Both these issues can lead to bias in the dataset and, subsequently, in the trained models.
Curating for Accuracy: The Role of Superb Curate
Superb Curate addresses these issues by providing a seamless way to search, manage, and visualize data. It automates the curation process, significantly reducing the costs associated with training, annotation, and infrastructure.
Key features of Superb Curate include:
High-dimensional embedding generation
Auto-curation for desired data scenarios
Target model performance using only a fraction of the data
The elimination of costly, time-consuming, and inaccurate manual curation
Enabling effective curation without systematic metadata collection or annotation
Industry Data Balance and Accuracy Use Cases
Across industries, Computer Vision (CV) models are widely utilized, each with its unique set of data balance and accuracy requirements. Superb Curate was designed to help ensure the accuracy of these models by addressing the specific challenges associated with unbalanced and inaccurate datasets.
Below are some typical industry use cases to explore:
Agriculture
In agriculture, CV models are employed for tasks such as crop disease identification and yield prediction. These models can suffer from class imbalance if there are fewer instances of certain crop diseases in the dataset. Using Superb Curate, the dataset can be curated to have a balanced representation of various crop diseases, improving the model's predictive accuracy.
Precision Agriculture and Livestock
Beyond crop disease identification and yield prediction, CV models also play a crucial role in precision agriculture and livestock management. In precision agriculture, CV models are used to analyze soil health, nutrient deficiencies, and irrigation needs based on aerial imagery.
However, factors such as the uneven spread of nutrients, differing soil types, and weather-induced changes can create data variability and noise. Similarly, in livestock management, CV models are deployed for animal identification, behavior analysis, and health monitoring. Challenges arise due to variability in animal appearance, behavior patterns, and lighting conditions in different environments.
Agricultural and Livestock Management
Superb Curate is incredibly effective in these scenarios. Its high-dimensional embedding generation feature can help account for the data variability and noise in these complex agricultural and livestock environments.
With the auto-curation feature, Superb Curate ensures the selected data is most suited for the specific needs of the CV models, thereby improving the overall accuracy and efficiency of precision agriculture and livestock management systems.
Moreover, with systematic metadata collection, the contextual information such as time of day, weather conditions, or location can be utilized to enhance the robustness of the CV models further.
2. Autonomous Vehicles
Autonomous vehicles rely heavily on CV models for tasks like object detection, lane detection, and traffic sign recognition. These models need to deal with extreme data variability and noise due to changes in weather, lighting conditions, and geographical locations. Superb Curate can help curate a robust dataset that encompasses this variability, enhancing the safety and reliability of autonomous vehicles.
Urban and Rural Driving Scenarios
For autonomous vehicles to operate safely and efficiently, CV models must also understand and adapt to varying driving conditions in both urban and rural environments.
In urban settings, the models must identify and interact with complex traffic scenarios, various road infrastructures, and numerous pedestrians. In contrast, rural settings present their own unique challenges, such as fewer lane markings, varying road quality, and different types of obstacles like wildlife.
Data Balance for Diverse Scenarios
The challenge lies in collecting a balanced dataset that accurately represents these diverse scenarios. Here, Superb Curate’s sophisticated auto-curation capabilities prove invaluable. It can ensure a balanced representation of both urban and rural driving scenarios in the training dataset, thereby improving performance of CV models across different environments.
Leveraging Metadata for Context
In addition, Superb Curate can use its metadata and annotation information to provide vital contextual details such as time of day, weather conditions, or region. These context-rich details can further increase the robustness and reliability of autonomous driving systems.
3. Manufacturing
Manufacturing units use CV for quality control to detect defective products. Data variability and noise can be a concern due to differences in lighting conditions and perspectives. Superb Curate's embedding generation feature can help curate a dataset that captures the variability in real-world manufacturing environments, thus enhancing the defect detection accuracy.
Continuous and Discrete Manufacturing
In the manufacturing sector, there are two broad types of production: continuous, such as chemical plants or oil refineries, and discrete, like electronics or automotive manufacturing. Each type presents unique challenges for CV models in terms of the variety of products, operational settings, and types of defects.
Defect Detection
In continuous manufacturing, a consistent process flow can lead to similar defects appearing with slight variations, making them hard to distinguish. In discrete manufacturing, on the other hand, the variety of parts and products increases the complexity of defect detection. A given CV model needs to discern a wide range of possible defect types, often under varying lighting conditions or from different perspectives.
Grouping Manufacturing Defects
Superb Curate's ability to generate high-dimensional embeddings can automatically group similar defects together, aiding in defect classification. Its auto-curation feature can balance the representation of various defect types in the dataset, ensuring the model is not biased towards more common defects.
Additionally, Superb Curate can utilize metadata to provide context about the manufacturing process, improving the model's understanding of different operational scenarios.
Working With Superb Curate
Managing Large Datasets
Superb Curate simplifies the uploading, pipelining, and managing of large volumes of data, including raw data, annotations, and metadata. The data is organized into datasets and slices for easy management and viewing.
This structure facilitates the easy management and viewing of data, enabling you to quickly identify and focus on the most pertinent information. This functionality directly addresses the challenge of handling immense data volumes and helps to avoid the diminishing returns associated with the "more the merrier" approach.
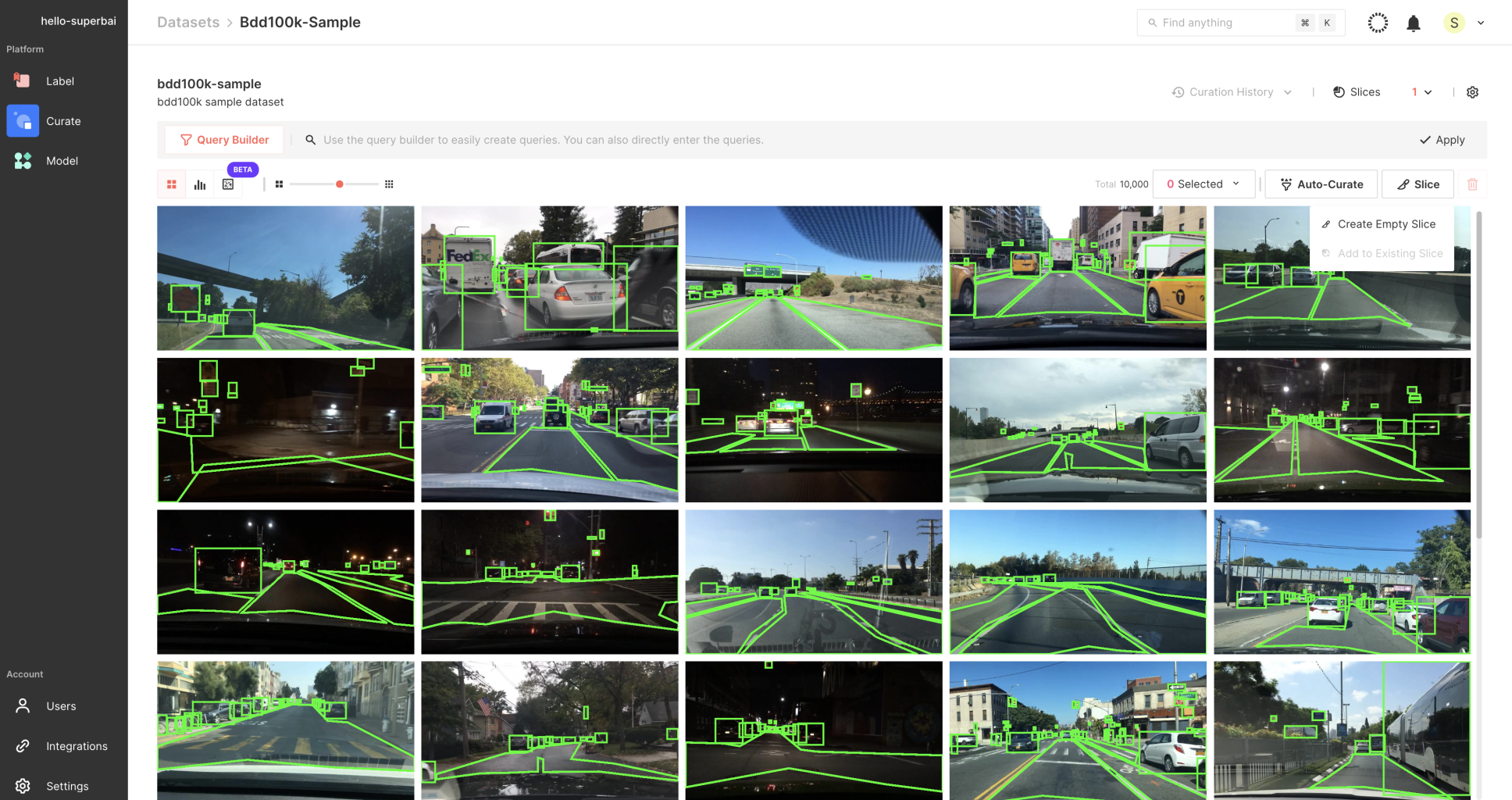
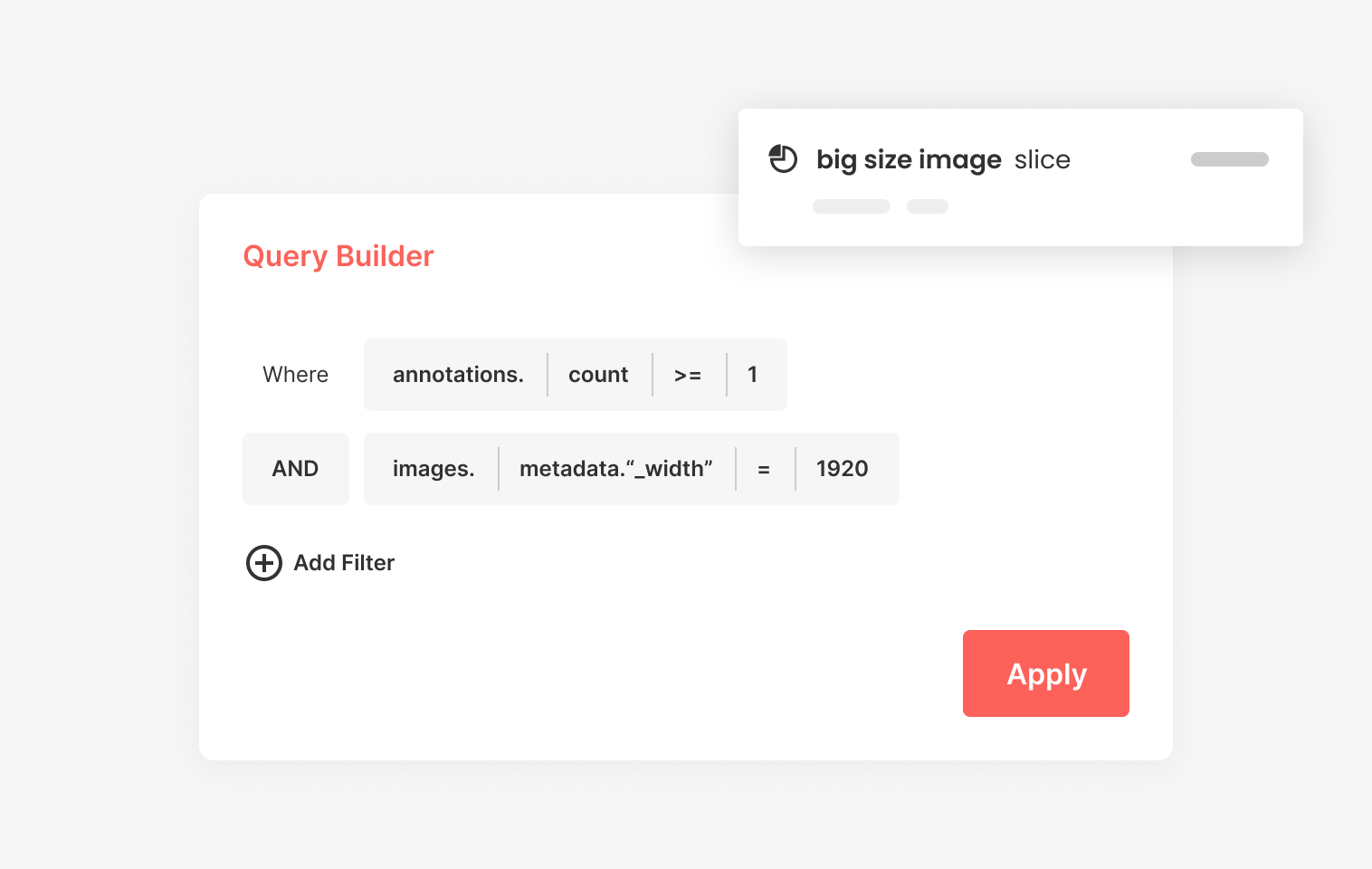
2.Simplifying Manual Search
Superb Curate also simplifies the process of manually searching for specific data using metadata and annotation information. This feature allows users to curate data for the diverse scenarios required for model development using straightforward query language.
By enabling efficient data searches, Superb Curate helps counteract the problems of class and scenario imbalance and data variability, paving the way for a more balanced and representative dataset.
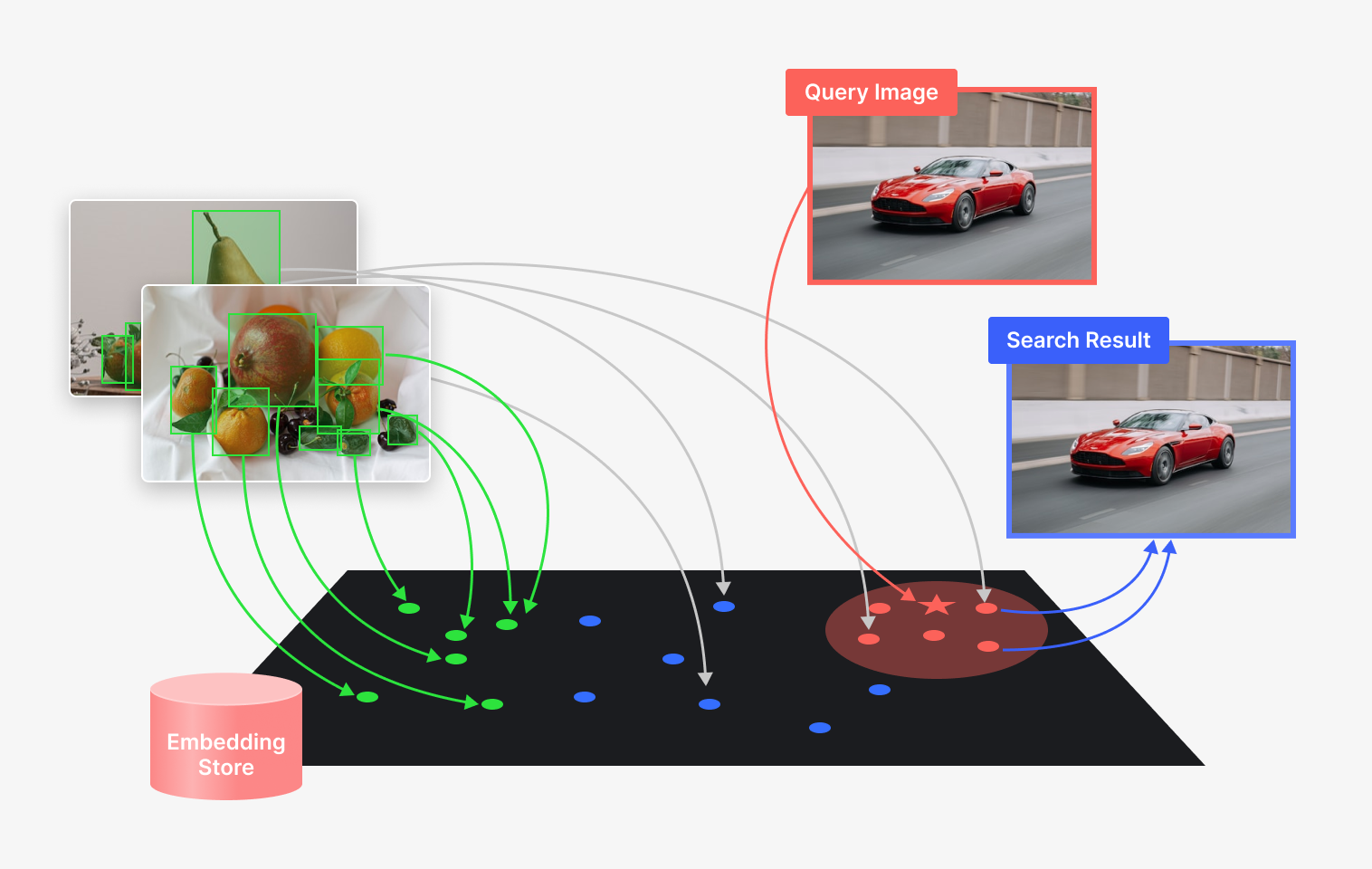
3. Embedding Generation
Superb Curate automatically calculates embeddings using proprietary, high-dimensional embedding generation algorithms whenever new data is uploaded. This feature allows automatic clustering of data without manual curation or custom embedding models. By doing so, it addresses the struggles of data variability and noise, and makes a significant leap towards the goal of balanced, representative datasets.

4. Auto-Curation
Superb Curate provides the ability to automatically curate the most suitable dataset for your model needs through the computation of visual similarity between data points. This feature reduces the cost of curation and helps in building a performant model with a more accurate and well-curated dataset.
This not only reduces the cost of curation but also aids in building a performant model with a more accurate and well-curated dataset. With this feature, the challenges of perfect random sampling and reliance on intuition are largely mitigated, leading to a more streamlined and reliable curation process.
5. View and Evaluate Data
Curate provides multiple ways to view and explore your datasets, making it easy to evaluate factors like similarity and data distribution. The views include grid view for a quick glance at the data, scatter view for detailed examination, and analytics view for in-depth analysis.
Each view offers a unique lens to scrutinize your data, thereby contributing to a thorough understanding of your dataset and aiding in the process of creating balanced and representative models.
Grid View

Scatter Plot View
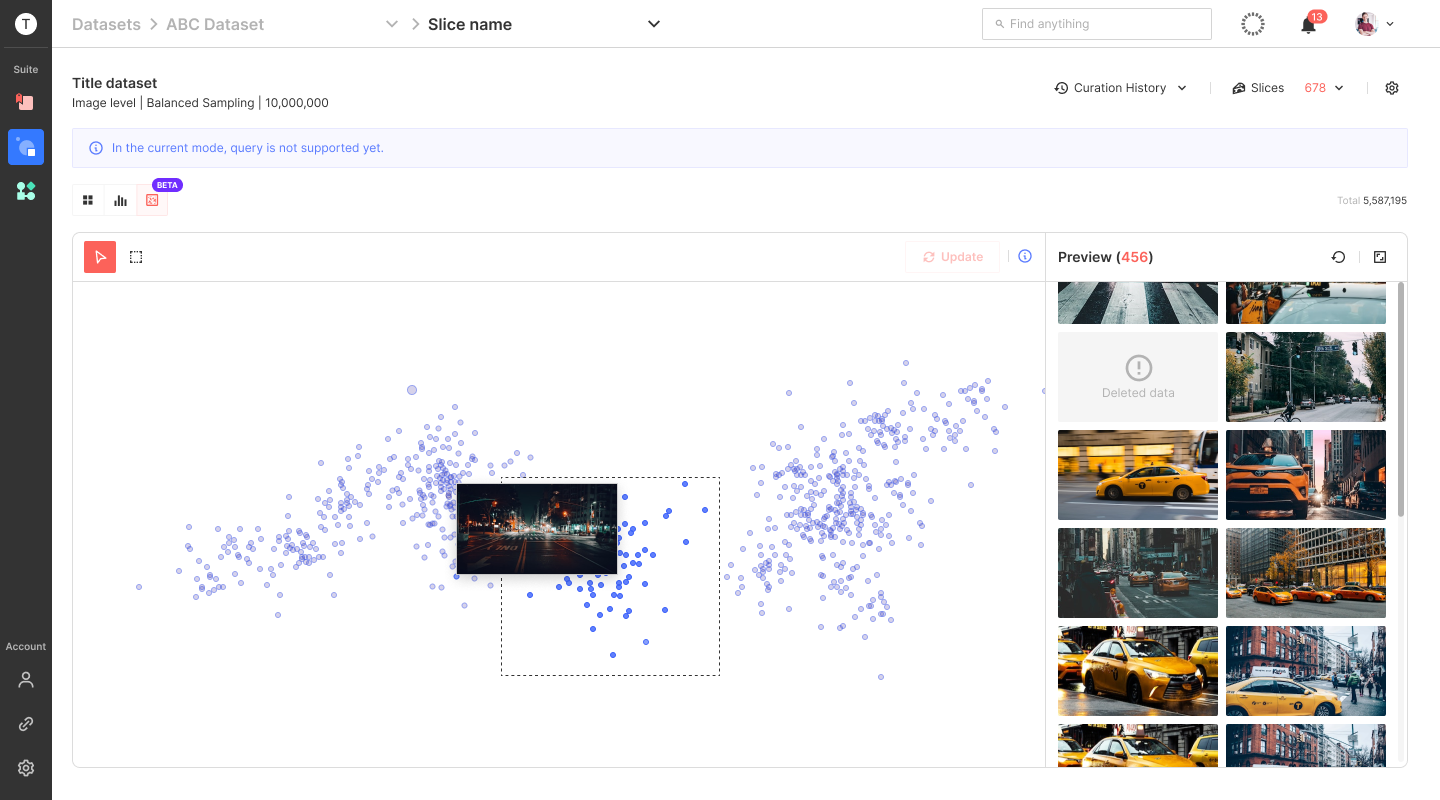
Analytics View
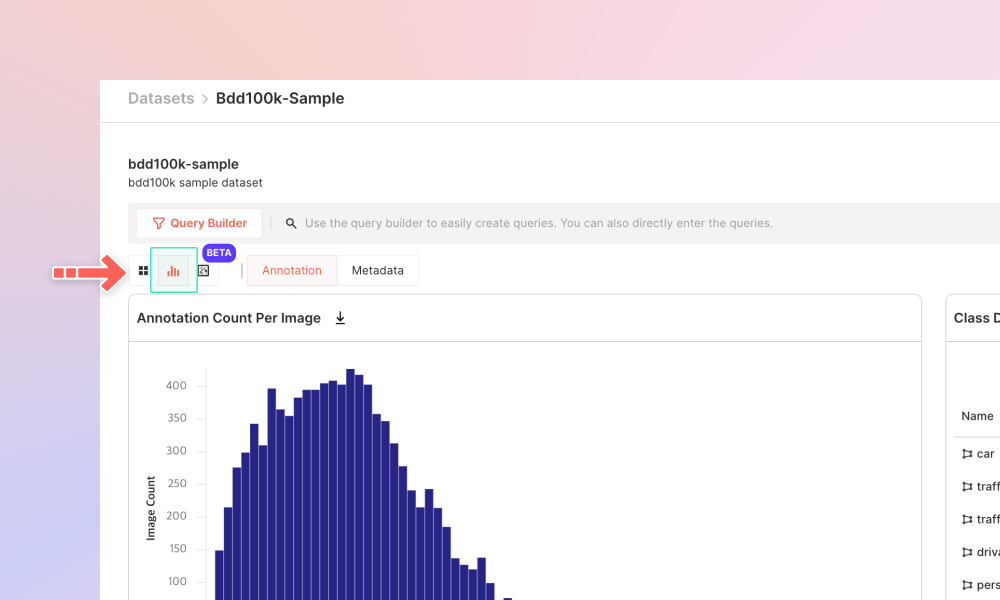
Curating for Precision and Balance
Superb Curate effectively addresses the common data challenges in building CV models. By providing a simplified and automated way to manage, search, curate, and explore data, it empowers users to curate their datasets effectively, ensuring more accurate and efficient CV models. For those seeking to overcome the hurdles in CV model development, Superb Curate is indeed a game-changing tool worth considering.
Superb Curate's capabilities aren't just limited to addressing the immediate challenges in data curation. Its holistic approach to data management, embedding generation, auto-curation, and explorative views empower its users to innovate continuously in the field of computer vision.
With such a robust tool, users can not only curate high-quality, balanced datasets but also have the opportunity to discover new insights, experiment with unique approaches, and push the boundaries of what's achievable in their respective fields.