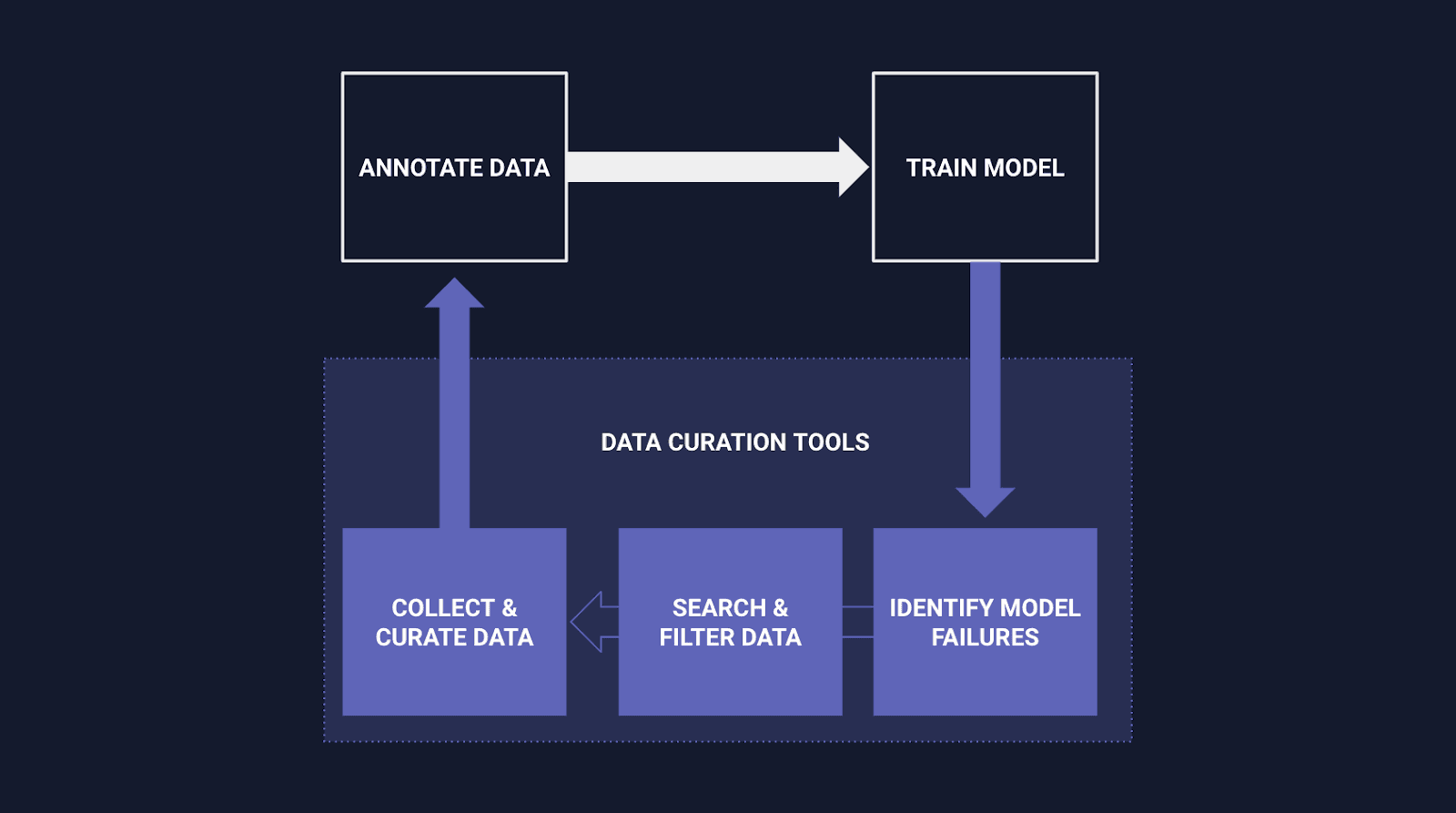
The concept of data curation has emerged as a vital process for machine learning development, bridging the gap between raw data and actionable insights. The procedure involves meticulous tasks such as data selection, data cleaning, image annotation, and data augmentation, particularly in the context of computer vision.
But data curation isn't merely about data collection; it's about choosing the right type of data—relevant, diverse, and representative of the problem at hand.
In this written adaptation of our in-depth webinar, we offer a thought-provoking lesson on the importance of data curation as the backbone of any successful machine learning project, as well as its role in ensuring fairness, transparency, and enhanced model performance.
The Power of Data Curation
Data curation is a critical process that involves organizing, integrating, and enhancing raw data to create a high quality dataset for machine learning models. It’s not only about collecting data, but about selecting the right type of data that is relevant, diverse, and representative of the problem we’re trying to solve.
In the context of computer vision, data curation tends to involve tasks like data selection, data cleaning, image annotation and data augmentation. This can be a meticulous process that requires not only a deep understanding of the data and the problem at hand, but also the context in which the data will be used. This includes the problem space, the intended use of the model, and the potential biases that could be introduced during the curation process.
The Backbone of Machine Learning Projects
Data curation is the backbone of pretty much any successful machine learning project, as the quality of your data directly impacts the performance of your models.
By creating your own data, you can ensure that models are trained on relevant high-quality data which will lead to more accurate predictions, more specifically, effective data curation can help mitigate common issues like class imbalance and biases in your data. It’s a pretty crucial step that bridges the gap between the raw data and actionable insights.
Fairness and Transparency
Data curation is not just about improving model performance, it’s also about better understanding your models and ensuring that they’re fair, ethical, and transparent. By creating data mindfully, you can ensure that your model reflects the diversity and complexity of the real world, leading to more fair and equitable outcomes.
Enhancing Model Performance
As stated, data curation plays a pretty direct role in enhancing model performance. When you create data, you’re essentially providing your model with a better learning environment.
This includes ensuring that your data is diverse and representative, which will help a model generalize better to unseen data that also involves cleaning your data to remove any noise or errors that could mislead your model. In essence, the better your data curation, the better your model performance.
Building Trust and Understanding
But it’s not just about performance. It’s also about trusting that your data was curated carefully. You can build trust in your models, ensuring that they make sense to users and stakeholders and that they can be relied upon to make important decisions.
Understanding the relationship between data problems and model performance is key to effective data curation. If your model is struggling with a certain class, it could be due to a lack of representative samples in your dataset.
Applying Curation to Real Scenarios
To cite some scenarios, a particular creation workflow could involve identifying and adding more samples of a certain class. Similarly, if your model is overfitting it could be due to an overly complex model or lack of diversity in training data.
That might mean the curation workflow involves augmenting data or collecting more diverse samples. This process is iterative and is going to require a deep understanding of both the data and the model. It’s about finding the right balance between the complexity of the model and the diversity of the data.
Traditional Curation: Pros and Cons
Traditional curation methods have been a cornerstone in the data management and preprocessing landscape, utilized across various domains. These techniques, which include random sampling and metadata-based curation, possess inherent simplicity and directness, allowing users to filter, organize, and utilize their datasets effectively.
While these methods provide a level of control and specificity in data collection, they come with their fair share of limitations and challenges.
Random Sampling
Random sampling is a traditional approach to data curation where a subset of data is selected. This is probably one of the most common methods of curation because it’s simple and easy to implement. But random sampling has its limitations, for instance, it might not capture the full diversity of the data set; particularly in cases where certain classes or features are underrepresented.
It also doesn’t take into account the relevance of quality of the data which could lead to suboptimal model performance. In the context of large and diverse datasets, random sampling might miss out on important patterns or relationships in the data. This can potentially lead to models that are not robust or that fail to generalize well to unseen data.
Metadata-Based Curation
Meta-based curation is another traditional approach where data is curated based on its metadata such as labels or annotations. This approach can be more targeted than random sampling which allows for more specific and relevant data selection. However it relies heavily on the quality and completeness of the metadata, which can be a pretty severe limitation.
The metadata also might not actually capture the full diversity of the dataset, especially in cases where it doesn’t full represent all the characteristics of the metadata might be incomplete, inaccurate, or biased and it might vary in quality across the data set. Particularly when working with data gathered from multiple sources.
Oftentimes, data scientists and machine learning engineers are working down the pipeline from where data is gathered and so can be limited in their options to change or improve on metadata. So while metadata can provide valuable insights for data curation and it can be a very useful starting point, it’s often limited to its efficacy and we have to look elsewhere for deeper insights about raw data.
The Pitfall of Traditional Curation
While traditional data curation methods are effective to some extent, they come with limitations. First, they often provide an incomplete representation of data. This is because they rely on manual labeling and metadata, which may not capture all the nuances and complexities of the data. Second, the more advanced methods are time consuming and labor-intensive, requiring significant human effort to curate and label the data.
This not only slows down the process, but also increases the risk of human error and bias. Third, more sophisticated traditional methods struggle with handling large data sets. As the volume of data grows it becomes increasingly challenging to manage and curate the data effectively and lastly these methods can have limited scalability and adaptability, they’re not designed to evolve or change specific data needs, making it difficult to keep pace with advancements in the field of computer vision.
Unlocking Embeddings for Curation
Embeddings are an extremely powerful tool in machine learning and computer vision. Essentially, they’re a form of feature extraction or feature learning, where raw input data such as images or natural language gets converted into a lower dimensional continuous vector representation.
These vector representations or embeddings encapsulate relationships and patterns in the data making it easier for machine learning algorithms to make accurate predictions or classifications.
Embeddings can offer several benefits, particularly in the case of unstructured data, such as raw, unlabeled images - enabling practitioners to handle large data sets more efficiently, improve model performance and gain deeper insight into the underlying structure of the data.
There are various types of embeddings, including those developed using convolutional neural networks or CNNS, autoencoders and pre-trained networks. Embeddings have a wide range of use cases from each generation and style.
Making Unstructured Images Searchable
One of the key things we can do with embeddings generated from visual data is to make a potentially vast amount of unstructured unlabeled images searchable by visual similarity. We do this by transforming each image into a vector as discussed using a convolutional neural network and then we can use a K-nearest neighbors algorithm to find the images that are closest to the given image in the vector space.
Capturing Granular Features with Embeddings
Depending on the techniques we’re using, embeddings can capture similarity at the image level such as lighting or time of day, but also at the level of more granular features such as the presence of specific objects.
There are a wide range of ways in which we can capture information about images and embeddings through vector space analysis, some being specific image retrieval, for recommendations systems, for photo managers and much more.
Deep Learning Models for Embeddings
One popular approach to single out is the use of deep learning models like CNNs or autoencoders, which are trained to figure out a compact, lower dimensional version of input data.
Pre-Trained Networks and Transfer Learning
Another good method is to take advantage of pre-trained networks and transfer learning. These pre-trained networks have already been trained on big data sets and have learned how to extract useful features from the data.
We can use these learned features for our own tasks which is called transfer learning. These pre-trained networks have already been trained on big datasets and have learned how to extract useful features from the data. We can use these learned features for our own tasks, which is called transfer learning.
Visualizing Embeddings
Once we have our embeddings, we can make them visual by using techniques like t-SNE or PCA to reduce the dimensions and potentially display the embeddings in a two-dimensional space. Something easily possible by the human eye so here we see an example of this sort of 2D visualization and this is from within the Superb AI Curate platform.

This gives us interesting information about the general visual structure and content of our dataset and it lets us pick out sets of visually similar or distinct images. We can see long sleeve and short sleeve t-shirts are selected, and a huge suave of shoes that have been identified as visually similar by the embeddings algorithm, from high yield to blog to sneakers.
Improving Embeddings
Once these embeddings have been generated we’re not done. It’s important to check and improve our embeddings. We can do this by seeing how well they perform certain tasks or fine-tuning them with our own data. Finally, as mentioned above, these embeddings have practical uses in image retrieval and recommendation systems, but critically, they can be used to take curation and organization to the next level.
Superb Curate
Superb Curate is a tool using embeddings designed to revolutionize the data curation process in computer vision. To start, we’ll discuss how embeddings are used when images are brought into the Superb Curate platform.
The first step is to generate embeddings for each of the images that have been uploaded. In the example below, we’ve generated a 1,024 dimensional vector to represent each image using a combination of embedding algorithms.

Generating Embeddings in Curate
We collapse this vector from 1,024 dimensions to two dimensions so we can easily visualize it. That leads us to be able to see trends in this data and start to get clusters of visual similarity images that are relatively distinct from the rest of the dataset.
As mentioned, Curate enables users to search their data by similarity and it’s possible to do so even at scale. If we want to pull out a really specific type of data for labeling and training we can easily select a subset of this data and add it to a slice.

This is a powerful way to quickly extract meaningful subsets of data without relying on metadata or human labeling, as well as a straightforward and powerful avenue to take in manually using embeddings to understand more about your data and to select or build out similar subsets.
However, when we talk about selecting subsets of data, there’s the broader question that should be asked. The one that’s fundamental to every model training pipeline. Almost anyone working to create labeled data in the computer vision space has more data than they can immediately label and as such, we have to select a subset of that data to label first.
Even if we’re planning on labeling all collected data, selecting that first subset and subsequent subsets is critical to an effective and efficient labeling workflow.
Iterative Active Learning
At Superb AI, we think one of the best ways to label a large quantity of data is with an iterative active learning model; first labeling a small subset, training a labeling model and using it to generate initial labels for the next subset. Correcting these automatic labels, training a new model, and so on. Having the most effective model as soon as possible can slash an ML team’s total labeling times.
To demonstrate this feature, we’re using a slightly larger dataset, the MNIST handwriting dataset. We can see the overall clustering of this set contains about 70,000 images, all unlabeled.
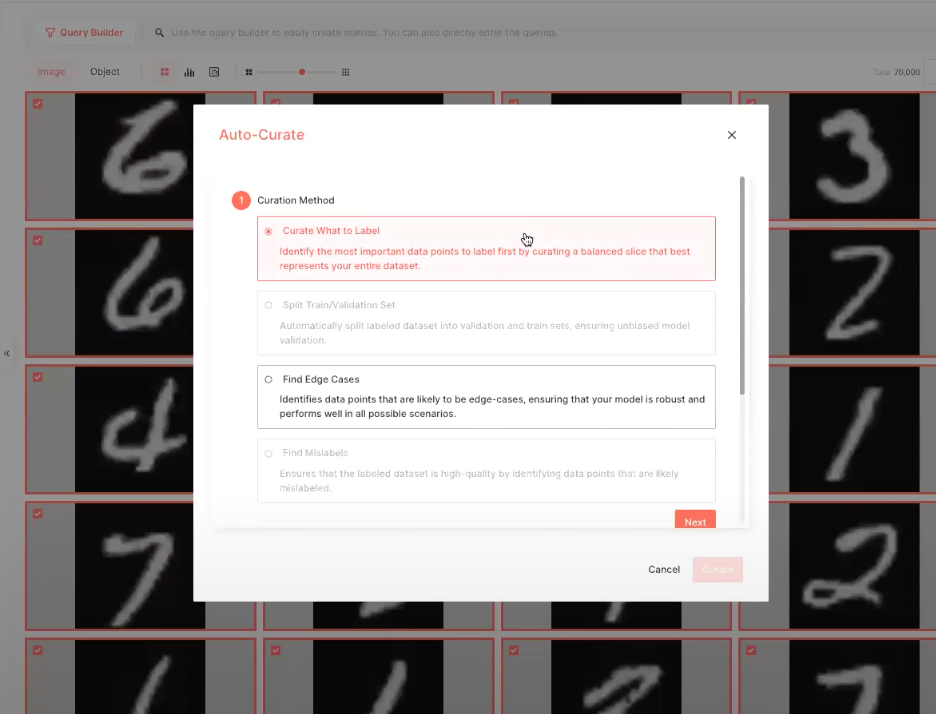
We pick out an initial subset to send to our labeling data, and it’s as simple as select the Auto-Curate function, selecting what to label; in this case, we’re only working with unlabeled data, then picking an subset, let’s say 20,000 images, then we pick the name of the slice to add it to.
Curation Review and Reports
Every Auto-Curate process that is run will create one or more slices of data which can then be reviewed, sliced further, added to, or sent back over to the label portion of Superb Suite for labelers to work on. We can review these slices in the slices tab, or just directly via the curation history by clicking on the slices.
Equally important to note is that each of these processes will create a report which allows us to see how this embedding-based algorithmic data creation process will work or is actually working so we see this type of reporting as critically important to any data creation process.
It’s important to understand exactly how and why subsets are curated so that models are transparent but also ethically built, starting at a high level. For the purpose of this report, we always compare our curated subsets with a randomly selected subset of the same size.
It’s the core process in generating the 1,024 dimensional embedding space referenced earlier. We group the images into clusters of varying sizes so we can say that these clusters are images that are semantically similar to each other.

Sparse clusters on the other hand, might only have a few images in them and these images don’t look a lot like other images in the dataset and as such, could be considered edge cases. These can be crucial for model training and it’s important to ensure that they’re well represented.
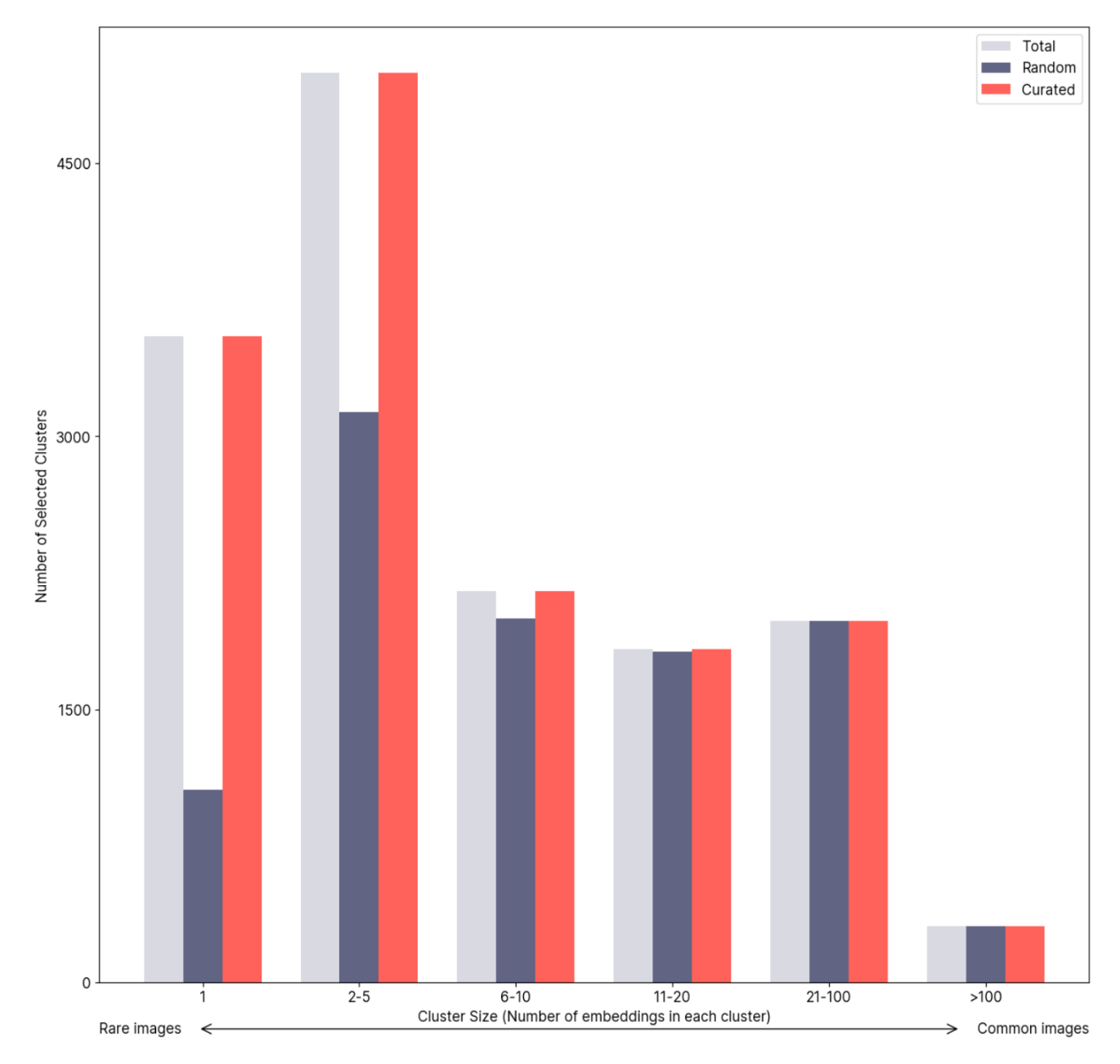
In a report we can see that the algorithm has grouped the data into almost 15,000 distinct clusters, a random sampling has only selected data from about two-thirds of these clusters while our curation has selected data from 100 percent.
Through the report, we can start to see the way in which the Auto-Curate algorithm pulls ahead of a random sampling with larger clusters. It’s pretty probable that a random sampling will select some images from the cluster, but with smaller clusters that becomes increasingly unlikely for clusters of one size.

Pioneering Advanced Data Curation
Data curation, particularly in the context of machine learning and computer vision, is an integral process in bridging the gap between raw data and actionable insights. It's more than mere data collection; it involves meticulously selecting, cleaning, annotating, and augmenting data, ensuring that it is relevant, diverse, and representative of the problem at hand.
Embeddings serve as a powerful tool in this arena, especially for handling unstructured data such as raw, unlabeled images. They enable data to be made searchable, capturing granular features, and contributing to a myriad of applications.
Superb Curate stands out as a promising tool in this field, using embeddings to revolutionize the data curation process, aiding in data selection and organization, and facilitating an iterative active learning model for efficient labeling workflows.
Below you’ll find the transcribed Q&A session for this webinar. The transcription presents the insightful questions raised by attendees and the responses provided by the presenter. They span from the process of dimension selection, edge case detection features, and much more, offering more details into the practice of data curation and the relevant capabilities of our tool, Superb Curate.
We hope that it, along with this adaptation of our event, provides valuable knowledge and direction in optimizing your machine learning projects.
Q: How are two dimensions chosen from the 1,024 dimensions.
A: So we’re not just picking two we’re reducing the 1,024 and in this case we can use a number of techniques like TC or PCA I think we use a variety of TC although that’s somewhat our secret sauce.
Q: Can you talk about edge case detection more?
A: We’re clustering images into groups based upon how closely semantically related they are to other images. Edge cases are images that are not similar to any other images. They’re in a group of one or a group of just a few.
Q: Will concentrating on edge cases deteriorate the performance for the majority?
A: That’s a really good question and it’s something we’re definitely considering. We recommend to keep the “common case” data and add edge cases gradually and see when you reach the optimal model performance. How much edge case will start causing deterioration in model performance for the majority depends on each case and there is no clear-cut optimal number or percentage.
Q: Is there a measure of edge case saturation to determine if the analysis of edge case will drift the central population.
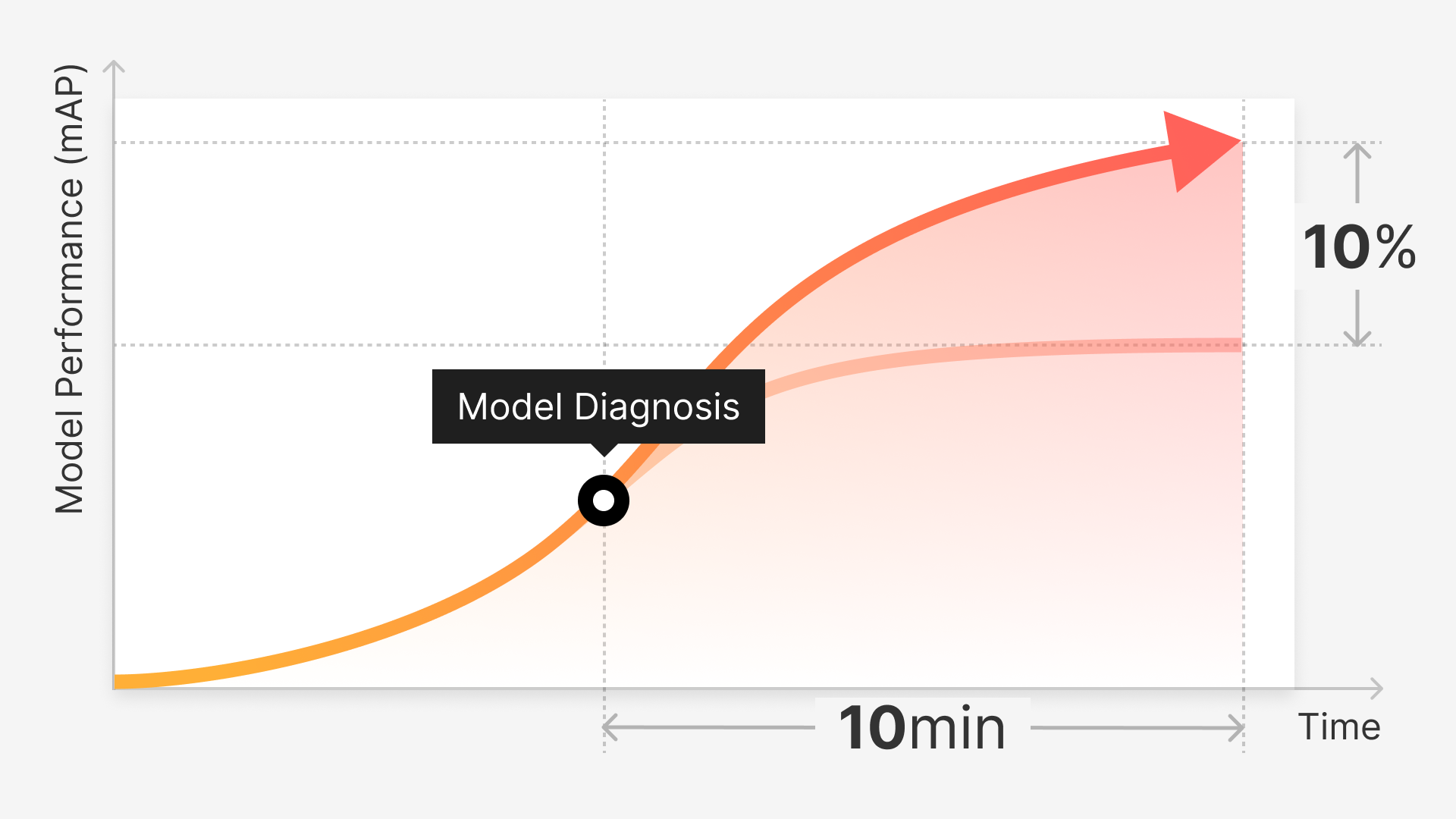
A: That’s not currently a part of Superb Curate but something that we’re working on. Our upcoming "Model Diagnosis" and "Model Monitoring" features will help diagnose/monitor this and will allow users for a quick iteration of their models to test performance on different training data.
Q: Are there any unique selling points of Superb AI you want to comment on?
A:
High-quality embedding models provided out-of-the-shelf not only for images, but also for objects (there are a few competitors providing image-level embeddings, but they are fairly low-quality compared to ours - as they only use one embedding model usually - and don't provide them for object data
Proprietary Auto-Curate algorithm that provides a one-click data curation based on various user scenarios and needs
Providing the Suite with Superb Label & Model that completes the MLOps cycle in one platform. For instance, you can train a model on Superb Model with curated train/validation set from Superb Curate and diagnose the performance of the model trained on Superb Model in a data-centric way on Superb Curate.
.
Q: Have you tried video cases?
A: That’s a good question, we’ve done a little bit of experiment with video cases. I would say that both sorts of curation work most effectively when we have a diverse dataset that we need to select a subset from. If we’re working with video frames there tends to be a lot of semantic similarity between video frames, which can make the algorithm a bit less effective, but this is something that we’re still experimenting on and equally we’re quite curious if this sort of technique can be used to extract the most significant frames from a video or frames with specific objects present. This is something we’re definitely continuing to work on although up until now our experimentation has been on image datasets.
Q: Guessing you are sampling for the Scatter Plot visualization since it would be too dense if you used all. If sampling, are you using a specific strategy or just random?
A: We use UMAP to reduce the embedding vector’s dimensions down to 2D. Our sampling method is a bit more sophisticated than just random sampling to ensure that rare, edge-cases that don’t form clusters are well represented in the scatter plot. To sample our data, we use spatial information of the embedding space. We basically draw XY coordinates (tiles) on the embedding space and make sure we sample evenly from each tile to make sure the 2D projection matches the actual representation of the data.
Q: Would reducing the multiple dimensions to 3 instead of 2 glean any additional granularity?
A: The actual dimensions of our embedding space is ~1024, so bringing it down to 2D or 3D doesn't have too much "technical" difference in terms of how well the data is clustered. On top of that it’s not always easy to visualize patterns and clusters in 3D, and much difficult to segment out regions or clusters in 3D.
Q: What's the base model? Is there an option to change it in the product?
A: The embedding/curation models are based on a combination of CLIP, DINO, and BEiT. How they interact together is part of our proprietary technology. As of right now, the models are static and all three models are used when calculating embeddings. In the future, we plan to upgrade or add embedding models (DINOv2 or SAM) and even allow users to bring/upload their own embedding models.
Q: What machine learning algorithm is used to find out the mislabeled data?
A: It’s a proprietary algorithm. In essence, object instances that are visually similar (have similar embedding vector values) but have different class tags assigned to them are regarded as having high probability of being mislabels.