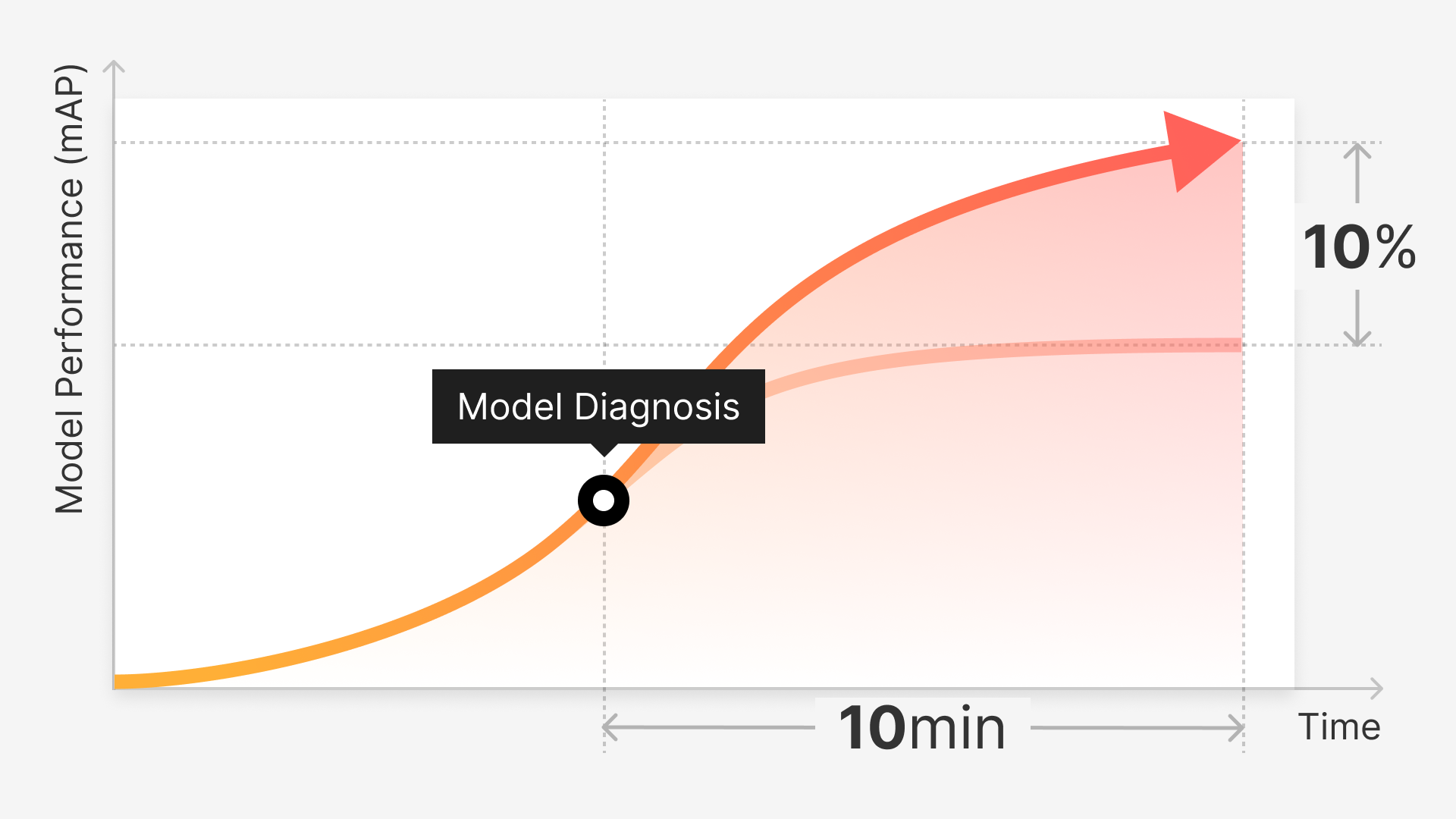
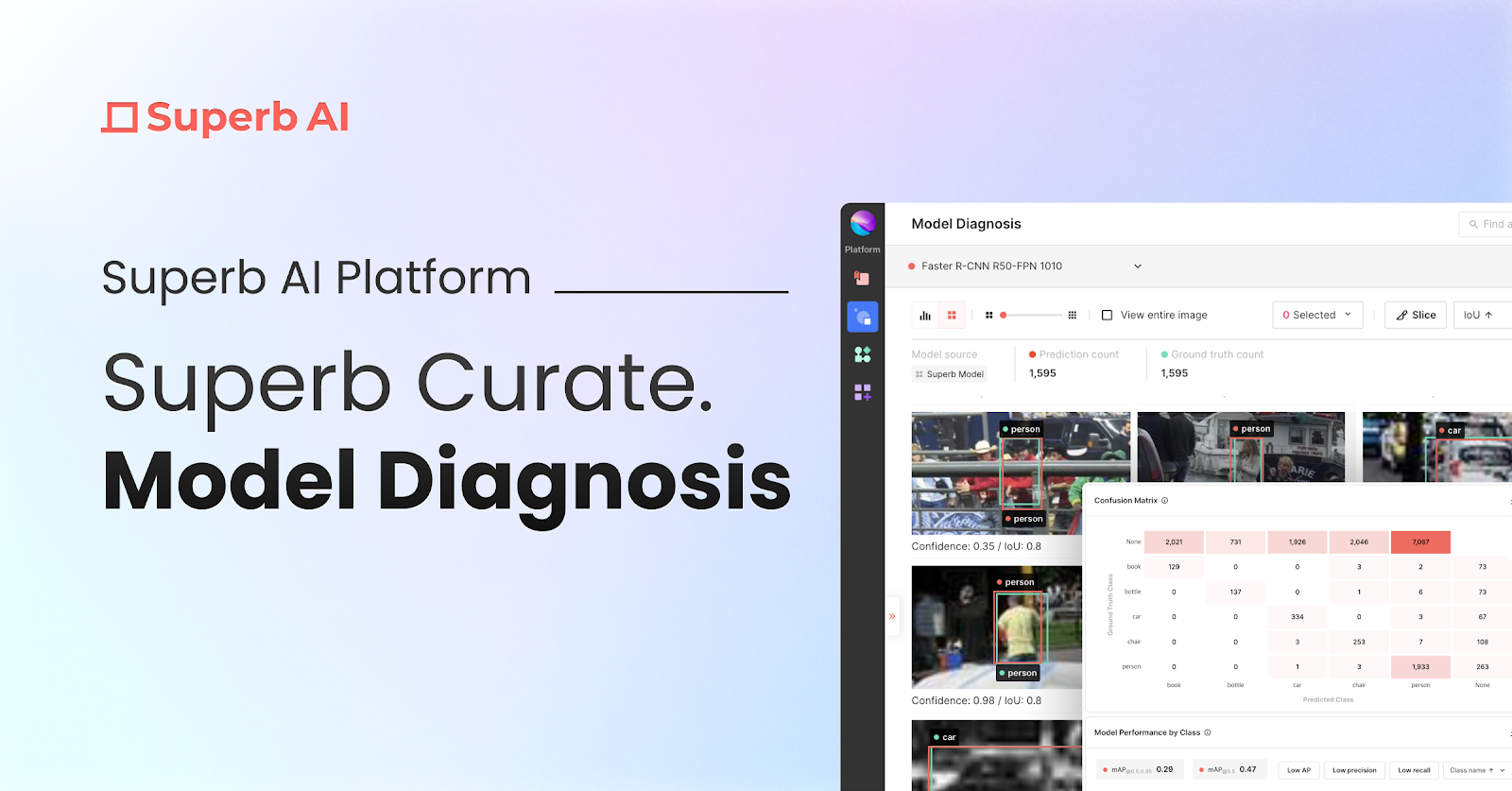
Introduction
We are excited to announce the newly improved Superb AI’s Custom Auto-Label product that automates the data labeling workflow to help computer vision teams drastically and reliably develop Long-Tail Computer Vision (CV) models.
If you’re building a real-world CV application, you have to invest in strategies and tools to help solve the long tail of real-world scenarios. For instance, the first 90% of the problem can be solved by addressing the most frequent cases that your product will encounter in the field. To get to 99%, you solve for variations and infrequent scenarios, but still commonly observable in the world. As you go deep to the 99.99..%, you are up against extremely rare scenarios. Building commercially viable and accurate CV applications with excellent user experience requires engineers and researchers to find and solve these rare scenarios.
Superb AI’s Custom Auto-Label allows CV teams to:
• Quickly spin up a model trained on their specific datasets for rapid labeling
• Manually Automatically surface hard labels with a combination of uncertainty estimation and active learning techniques
• Build optimized ground truth datasets while retraining models for future iterations
• Expand to novel use cases in rare scenarios with unique conditions and heavy subject matter expertise
In this blog, we’ll talk about our obsession with the data labeling problem, the common challenges of labeling data for long-tail CV, then go into more detail about Superb AI’s Custom Auto-Label capabilities.
Our Obsession To Automate Data Labeling
As you can already tell, we’re obsessed with solving this pressing data labeling problem for the CV industry.
• Initially, we launched an auto-labeling feature based on a pre-trained model that accurately detects up to 100+ general object classes.
• Then, we built and layered on top our Uncertainty Estimation AI to measure the uncertainty of each auto-labeled annotation to speed up active learning workflows.
• Next, we introduced the initial version of our Custom Auto-Label, which uses a unique mixture of transfer learning, few-shot learning, and autoML - enabling the pre-trained model to learn on small customer-proprietary datasets quickly.
• Most recently, we released the Manual QA set of features built to streamline the label validation workflow so you can consistently collect high-quality labels without significant efforts.
As we invest more time speaking to more CV practitioners across the industry without bias for the domain, the company size, or the operational maturity, we are bullish that they need even more advanced automation and agile operations for their data labeling workflows in long-tail scenarios. Current supervised learning techniques tend to perform well on common inputs but struggle where examples are sparse. Since the tail often makes up most inputs, CV practitioners end up in an infinite loop of collecting new data and retraining models to account for edge cases. Ignoring the tail can be equally painful, resulting in missed customer opportunities, poor economics, and frustrated users.
The Data Labeling Challenge for Long-Tail Computer Vision
Based on our surveys and interviews, the data labeling bottleneck applies to teams that just started a new CV project and more mature teams with models already in production.
1. Companies or teams in the early stages of ML development want to utilize AI in some ways, but they do not have any models pre-trained on niche or domain-specific datasets.
2. Mature teams with models in production are well-versed in the ML development and deployment lifecycle. They tend to have sophisticated pre-trained models and are focused on further improving model accuracy. They want to identify where the model is failing and manually prepare datasets to address those edge cases. They also want to address issues like data and model drift, where the accuracy of the trained model degrades over time as the characteristics of the data, upon which the model is trained on, change over time.
Underscoring on the technical challenges with labeling data for long-tail CV applications, we found that:
1. The images and videos that computer vision models see can be very dense. For example, images can have a lot of objects, making manual labeling very expensive.
2. Images in real life have various viewpoints and lighting. If you take a model pre-trained on clean open-source datasets and try to automate labeling, the model will likely not perform well under these conditions.
3. In order for the model to detect rare events, you want to collect unlabeled data in these rare events. Labeling these rare events with a pre-trained model is almost impossible when you don't have enough of these rare events, to begin with. This is a catch-22 situation.
Besides the technical challenges of preparing high-quality labeled data, there are also economic and operational challenges:
1. Labeled data has a cost to collect, process, and maintain. While this cost tends to decrease over time relative to data volume, the marginal benefit of additional data points declines much faster. When you rely on brute-force manual labeling, the labeling cost increases linearly, proportional to the number of labels created. What makes things even worse is that you will need exponentially more data and more money as your model performance improves. Unfortunately, your model performance plateaus as the number of labels increases. In other words, the marginal gain of your data diminishes to improve your model performance.
2. Collecting and labeling long-tail data in a repeatable way is a critical capability for most CV teams. This usually involves identifying out-of-distribution data in production, curating valuable samples, labeling the new data to be used as the new training set, and retraining models in an automated fashion. However, best practices for data operations are still nascent (we wrote about it here). We are working tirelessly with other members of the AIIA to help shape the playbook for operational best practices.
Because of these challenges, many CV teams choose to work only on simple use cases that do not require complex labeling instructions. Alternatively, some teams decide to invent their own techniques to automate data labeling, often at the cost of adding weeks or months to development timelines, and potentially limiting prediction accuracy due to distributional shifts between training and serving environments.
Superb AI’s Custom Auto-Label
Breaking down the key capabilities of Custom Auto-Label:
1. Reduce human verification time using uncertainty estimation: We have developed a proprietary “uncertainty estimation” technique with which a Custom Auto-Label model can measure how confident it is with its own labeling predictions. In other words, our Custom Auto-Label outputs annotations (i.e., bounding boxes and the corresponding object class) and simultaneously outputs how confident it is with each annotation. Therefore, it requests human verification only in cases it is uncertain about, reducing the amount of work that goes into manual label validation.
2. Adapt to new tasks with few data: Besides the common task of annotating object classes such as “person” or “car” with bounding boxes, there are myriads of different object classes, data domains, and labeling tasks. Generally, training a model on a new set of object classes, data domain, or labeling task requires a significantly large amount of labeled data. Until then, one must rely on the manual data labeling process. To remedy this problem and help our users benefit from Custom Auto-Label on long-tail data, we use a combination of transfer learning and few-shot learning to quickly adapt and tailor our proprietary models to your data in your specific application domain.
3. Exploit the labels that come with the data for free: Custom Auto-Label utilizes self-supervised learning to pre-train our models on popular application scenarios for computer vision. For your long-tail scenarios, you can select from our list of pre-trained models that have been self-supervised on each of these scenarios, which might work well for your domain.
With Custom Auto-Label, computer vision teams can retrain models that they have using a very small number of their data without any custom engineering work to audit model predictions faster. They can put more focus on business-critical aspects like model observability and scalable infrastructure for long-tail problems. Take a look at our Fox Robotics case study for an example.
Conclusion
Many organizations want to deploy cutting-edge computer vision applications with long-tail properties but struggle with their labeling requirements. Data labeling is often the most time-consuming process of implementing Long-Tail Computer Vision. Manual labeling or ineffective automated labeling can add weeks or months to a project’s delivery time.
At Superb AI, we have been hard at work building the most complete training data management platform in the industry. With our improved Custom Auto-Label product, we automate the most challenging step in the transition to Long-Tail Computer Vision: labeling images and videos with long-tail scenarios. We have several customers using our Custom Auto-Label in their workflows and are excited to bring this capability to new users.
If you’re building Long-Tail Computer Vision models and want to learn more, feel free to schedule a call with our Sales team. We’ll be happy to discuss your project in more detail.