データキュレーションの概念は、機械学習の開発において、生データと実用的な洞察とのギャップを埋める重要なプロセスとして注目されています。特にコンピュータビジョンの分野では、データ選択、データクリーニング、画像アノテーション、データ補強といった綿密な作業が必要となります。
しかし、データキュレーションとは、単にデータを収集することではなく、適切な種類のデータ、つまり、関連性があり、多様性があり、目の前の問題を代表するデータを選ぶことでなければなりません。
この記事では、機械学習プロジェクトを成功に導くバックボーンとしてのデータ・キュレーションの重要性と、公平性、透明性、モデル性能の向上を保証する役割について、示唆に富んだ内容をお伝えします。
データキュレーションの威力
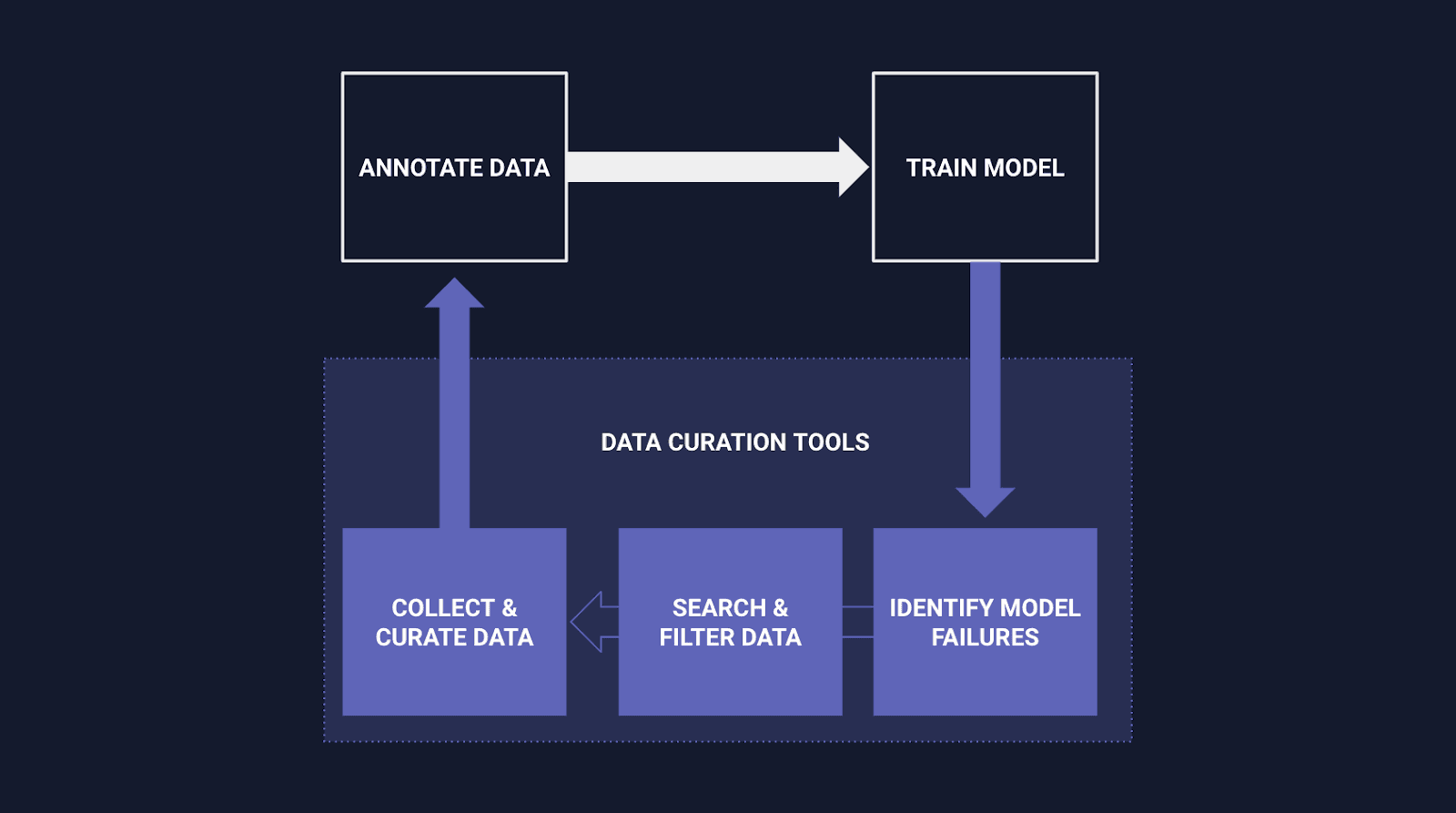
データキュレーションは、機械学習モデル用の高品質なデータセットを作成するために、生データを整理、統合、強化する重要なプロセスで す。データを収集するだけでなく、関連性があり、多様で、解決しようとしている問題を代表する適切なタイプのデータを選択することが重要です。
コンピュータビジョンの文脈では、データキュレーションはデータ選択、データクリーニング、画像アノテーション、データ補強などのタスクを含む傾向があります。これは綿密なプロセスであり、データと手元の問題を深く理解するだけでなく、データが使用されるコンテキストも必要となります。これには、問題の対象、モデルの使用目的、キュレーションの過程で導入される可能性のあるバイアスなどが含まれます。
機械学習プロジェクトのバックボーン
データの質はモデルの性能に直接影響するため、データのキュレーションは機械学習プロジェクトを成功させるための重要な要素でなのです。
独自のデータを作成することで、より正確な予測につながる関連性の高い高品質なデータでモデルを確実に学習させることができます。より具体的には、効果的なデータキュレーションは、データのクラス不均衡やバイアスなどの一般的な問題を軽減するのに役立ちます。これは、生データと実用的な洞察との間のギャップを埋める非常に重要なステップで す。
正確さと透明性
データキュレーションは、モデルのパフォーマンスを向上させるだけでなく、モデルをよりよく理解し、公正、倫理的、透明性を確保することでもあります。心してデータを作成することで、モデルが現実世界の多様性と複雑性を確実に反映し、より適正でより衡平な結果を導くことができるのです。
モデル性能の向上
前述の通り、データキュレーションはモデルのパフォーマンスを向上させる上でかなり直接的な役割を果たします。データを作成するということは、基本的にモデルにより良い学習環境を提供するということです。
これには、データが多様で代表的であることを確認することが含まれ、これによってモデルが未知のデータに対してより適切に汎化できるようになります。また、モデルを惑わす可能性のあるノイズやエラーを取り除くためにデータをクリーニングすることも含まれます。要するに、データキュレーションがうまくいけばいくほど、モデルの性能は向上するのです。
信頼と理解の構築
しかし、それはパフォーマンスだけの問題ではありません。データが注意深く管理されていることを信頼することでもあります。ユーザーや利害関係者にとって意味のあるものであり、重要な意思決定を行う際に信頼できるものであることを保証することで、モデルに対する信頼を築くことができるのです。
データの問題とモデルのパフォーマンスとの関係を理解することは、効果的なデータキュレーションの鍵で す。モデルが特定のクラスで苦戦している場合、それはデータセットに代表的なサンプルがないことが原因かもしれません。
実際のシナリオにキュレーションを適用する
いくつかのシナリオを挙げると、特定の作成ワークフローでは、特定のクラスのサンプルを特定し、さらに追加することが含まれます。同様に、モデルがオーバーフィットしている場合、それはモデルが複雑すぎるか、トレーニングデータに多様性がないことが原因かもしれません。
つまり、キュレーションのワークフローは、データを補強したり、より多様なサンプルを収集することを意味するかもしれません。このプロセスは反復的であり、データとモデルの両方を深く理解する必要があります。モデルの複雑さとデータの多様性の間で適切なバランスを見つけることが重要なの です。
従来のキュレーション: 長所と短所
伝統的なキュレーション手法は、データ管理および前処理における礎石であり、様々な領域で利用されてきました。ランダムサンプリングやメタデータベースのキュレーションを含むこれらの手法は、本質的にシンプルで直接的であるため、ユーザーはデータセットをフィルタリングし、整理し、効果的に利用することができます。
これらの方法は、データ収集においてコントロールと特異性のレベルを提供する一方で、それなりの限界と課題を伴います。
ランダムサンプリング
ランダムサンプリングは、データのサブセットを選択するデータキュレーションの伝統的なアプローチです。これはシンプルで簡単に実施できるため、おそらく最も一般的なキュレーションの方法の1つです。しかし、ランダムサンプリングには限界があります。例えば、データセットの多様性を完全に把握できない可能性があります。特に、特定のクラスや特徴が十分に表現されていない場合です。
また、データの質の関連性も考慮されていないため、モデルのパフォーマンスが最適化されない可能性があります。大規模で多様なデータセットの場合、ランダムサンプリングはデータ中の重要なパターンや関係を見逃してしまう可能性があります。これは、堅牢性に欠けるモデルや、未知のデータに対してうまく一般化できないモデルにつながる可能性があります。
メタデータに基づくキュレーション
メタベースのキュレーションは、ラベルや注釈などのメタデータに基づいてデータをキュレーションする、もうひとつの伝統的なアプローチで す。このアプローチは、ランダムサンプリングよりもターゲットを絞ることができ、より具体的で関連性の高いデータを選択することができます。しかし、メタデータの品質と完全性に大きく依存するため、かなり厳しい制限を受ける可能性があります。
メタデータもまた、実際にはデータセットの多様性を完全に捉えていないかもしれません。特に、メタデータがすべての特徴を完全に表していない場合、メタデータが不完全、不正確、または偏っているかもしれませんし、データセットによって質が異なるかもしれません。特に複数のソースから収集したデータを扱う場合はなおさらです。
多くの場合、データサイエンティストや機械学習エンジニアは、データが収集されたパイプラインの下流で作業しているため、メタデータを変更したり改善したりする選択肢が制限されることがあります。そのため、メタデータはデータキュレーションのための貴重な洞察を提供することができ、非常に有用な出発点となり得るが、その有効性には限界があることが多く、生データに関するより深い洞察を得るためには別の場所を探さなければなりません。
従来のキュレーションの落とし穴
従来のデータ・キュレーション手法はある程度有効ではあるが、限界も伴っています。まず、データの表現が不完全であることが多い。これは、手作業によるラベリングやメタデータに依存しているためで、データのニュアンスや複雑性をすべて把握しているとは限らない。第二に、より高度な方法は時間と労力がかかり、データのキュレーションとラベリングに多大な労力を必要とします。
これはプロセスを遅くするだけでなく、ヒューマンエラーやバイアスのリスクを高めます。第三に、より精緻な従来の手法は、大規模なデータセットの取り扱いに苦戦します。データ量が増えるにつれて、データを効果的に管理し、キュレーションすることはますます難しくなります。最後に、これらの方法は拡張性や適応性に限界があり、特定のデータニーズを進化させたり変更したりするようには設計されていないため、コンピュータ・ビジョン分野の進歩に追いつくことが難しくなります。
キュレーションのためにエンベッディングを活用する
エンベッディングは、機械学習やコンピュータビジョンにおいて非常に強力なツールです。基本的には、特徴抽出や特徴学習の一形態であり、画像や自然言語などの生の入力データを低次元の連続ベクトル表現に変換します。
これらのベクトル表現や埋め込みは、機械学習アルゴリズムが正確な予測や分類を行いやすくするために、データ内の関係やパターンを内包しています。
エンベッディングは、特にラベル付けされていない生画像のような非構造化データの場合に、いくつかの利点を提供することができます。それは大規模なデータセットをより効率的に扱い、モデルのパフォーマンスを向上させ、データの根本的な構造をより深く理解することが可能になります。
エンベッディングには、コンボリューション型ニューラルネットワークやCNNSを使用して開発されたもの、オートエンコーダ、事前に訓練されたものなど、さまざまな種類があります。エンベッディングは、それぞれの世代やスタイルから、幅広いユースケースを持っています。
構造化されていない画像を検索可能に
視覚データから生成された埋め込みでできる重要なことの1つは、ラベル付けされていない膨大な量の潜在的な画像を、視覚的な類似性によって検索可能にすることです。これは、コンボリューション型ニューラルネットワークを使用して説明したように、各画像をベクトルに変換し、K-nearest neighbors アルゴリズムを使用して、ベクトル空間内で与えられた画像に最も近い画像を見つけることで実現できます。
エンベッディングを使ったきめ細かな特徴の捕捉
使用する技術にもよりますが、エンベッディングは、照明や時刻といった画像レベルでの類似性を捉えるだけでなく、特定のオブジェクトの存在といった、より細かな特徴レベルでも類似性を捉えることができます。
ベクトル空間解析を通じて画像や埋め込みに関する情報を取得する方法は、画像検索、レコメンデーションシステム、写真管理など多岐にわたります。
エンベッディングのためのディープラーニングモデル
CNNやオートエンコーダのようなディープラーニングモデルは、入力データをよりコンパクトで低次元なものにするために学習させるものです。
事前学習済みネットワークと転移学習
もうひとつの良い方法は、事前に訓練されたネットワークと転移学習を利用する方法です。これらの事前訓練されたネットワークは、すでにビッグデータセットで訓練されており、データから有用な特徴を抽出する方法を学習しています。
これらの学習された特徴を、我々のタスクに利用することが可能であり、これを転移学習(transfer learning)と呼びます。これらの事前訓練されたネットワークは、すでに大きなデータセットで訓練されており、データから有用な特徴を抽出する方法を学習している。我々はこれらの学習された特徴を我々のタスクに使うことができ、これを転移学習と言います。
エンベッディングの可視化
埋め込みができたら、t-SNEやPCAのようなテクニックを使って次元を減らし、埋め込みを2次元空間に表示することができます。このような2次元可視化の例をSuperb AI Curateプラットフォームで見てみましょう。

エンベッディングの改善
いったんエンベッディングを生成したら、それで終わりではありません。データをチェックし、改善することが重要です。これは、あるタスクがどの程度実行されるかを見たり、私たち自身のデータで微調整したりすることで可能です。最後に、上述したように、これらのエンベッディングは、画像検索や推薦システムにおいて実用的な用途がありますが、決定的に重要なのは、キュレーションや 構成を次のレベルに引き上げるために使用できるということです。
Superb Curate
Superb Curateは、コンピュータビジョンのデータキュレーションプロセスに革命を起こすために設計された、エンベッディングを利用したツールです。まず始めに、Superb Curateプラットフォームに画像を取り込む際に、埋め込みがどのように使われるかについて説明します。
最初のステップは、アップロードされた各画像の埋め込みを生成することです。下の例では、埋め込みアルゴリズムを組み合わせて、各画像を表現する1,024次元のベクトルを生成しています。

Curateでエンベッディングを生成する
このベクトルを1,024次元から2次元に折りたたみ、簡単に視覚化できるようにします。そうすることで、このデータの傾向を見ることができるようになり、他のデータセットとは比較的異なる視覚的類似画像のクラスターを得ることができるようになるのです。
前述したように、Curateはユーザーが類似性によってデータを検索することを可能にしており、それは規模が大きくなっても可能です。ラベリングやトレーニングのために本当に特定の種類のデータを抽出したい場合は、このデータのサブセットを選択してスライスに追加することが簡単にできます。

しかし、データの部分集合の選択について語るとき、より広範な疑問が生じます。それは、すべてのモデル学習パイプラインにとって基本的な質問です。コンピュータ・ビジョンの分野でラベル付きデータを作成しようとしているほとんどの人は、すぐにラベル付けできるデータよりも多くのデータを持っています。そのため、最初にラベル付けするデータのサブセットを選択する必要があります。
収集したデータすべてにラベル付けをするつもりであっても、最初のサブセットとその後のサブセットを選択することは、効果的で効率的なラベル付けワークフローにとって重要な意味を持ちます。
反復アクティブラーニング
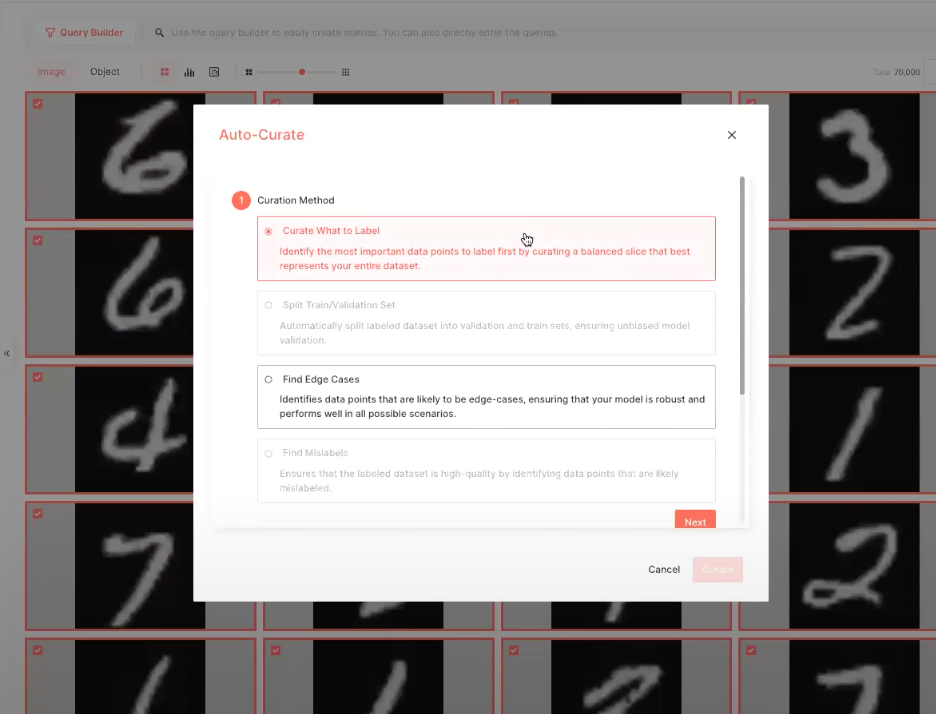
Superb AIでは、大量のデータにラベル付けする最良の方法のひとつは、反復型の能動学習モデルだと考えています。まず小さなサブセットにラベル付けを行い、ラベル付けモデルをトレーニングし、それを使って次のサブセットの初期ラベルを生成します。これらの自動ラベルを修正し、新しいモデルをトレーニングする、といった具合で繰り返し行います。できるだけ早く最も効果的なモデルを持つことで、MLチームの総ラベリング時間を短縮することができます。
この機能を実証するために、少し大きめのデータセットであるMNIST手書きデータセットを使います。このセットの全体的なクラスタリングには、すべてラベルのない、約7万枚の画像が含まれていることがわかります。
キュレーションのレビューとレポート
Auto-Curateプロセスを実行すると、データのスライスが1つ以上作成されます。このスライスをレビューしたり、さらにスライスしたり、追加したり、Superb Suiteのラベル用に送り返したりすることができます。これらのスライスは、スライスタブで確認することもできますし、スライスをクリックしてキュレーション履歴から直接確認することもできます。
同様に重要なのは、これらのプロセスのそれぞれがレポートを作成することで、エンベッディングに基づくアルゴリズムによるデータ作成プロセスがどのように機能するか、あるいは実際に機能しているかを確認することができます。
モデルが透明でありながら倫理的に構築されるように、サブセットがどのように、そしてなぜキュレートされるのかを、高いレベルから正確に理解することが重要であると考えています。本レポートでは、キュレートされたサブセットと、無作為に選ばれた同じサイズのサブセットを常に比較しました。
これは、先に言及した1,024次元の埋め込み空間を生成する中核となるプロセスです。画像をさまざまな大きさのクラスタにグループ分けすることで、これらのクラスタは互いに意味的に類似した画像であると言えます。

一方、疎なクラスタには数枚の画像しかない場合があり、これらの画像はデータセット内の他の画像とあまり似ていないため、エッジケースとみなされる可能性があります。このような画像はモデル学習にとって重要であり、適切に表現することが重要です。
レポートでは、アルゴリズムがデータを約15,000の異なるクラスターにグループ分けしていることがわかります。ランダムサンプリングでは、これらのクラスターの約3分の2からしかデータが選択されないのに対し、私たちのキュレーションでは100%からデータが選択されています。
レポートを通して、Auto-Curateアルゴリズムが、より大きなクラスターでランダムサンプリングよりも優位に立つ方法が見えてきました。ランダムサンプリングがクラスターからいくつかの画像を選択する可能性はかなり高いですが、クラスターが小さくなると、1つのサイズのクラスターではその可能性はますます低くなります。


先進的なデータキュレーションの開拓
データキュレーションは、特に機械学習とコンピュータビジョンの分野では、生データと実用的な洞察のギャップを埋めるために不可欠なプロセスです。単なるデータ収集にとどまらず、綿密にデータを選択し、クリーニングし、アノテーションを施し、補強することで、関連性があり、多様で、目の前の問題を代表するものであることを保証しなければなりません。
エンベッディングはこの分野で、特にラベル付けされていない生画像のような非構造化データを扱うための強力なツールとして機能します。データを検索可能にし、きめ細かな特徴を捉え、無数のアプリケーションに貢献します。
Superb Curateは、この分野で有望なツールとして際立っています。データの選択と整理を支援し、効率的なラベリングワークフローのための反復能動学習モデルを促進し、データキュレーションプロセスに革命をもたらすエンベッディングを使用しています。
以下では、このウェビナーで行われた質疑応答セッションを文字起こししたものをご覧いただけます。このテープ起こしでは、参加者から寄せられた洞察に満ちた質問と、プレゼンターからの回答をご紹介します。次元の選択プロセス、エッジケースの検出機能など、データキュレーションの実践と弊社ツールSuperb Curateの関連機能について、より詳細な情報を提供しています。
機械学習プロジェクトを最適化するための貴重な知識と方向性を、このイベントの翻案とともに提供できれば幸いで す。
Q: 1,024の次元から2つの次元はどのように選ばれるのですか?
A: 単に2つを選ぶのではなく、1,024を減らすのです。この場合、TCやPCAのような多くのテクニックを使うことができます。
Q: エッジケースの検出について、もう少し詳しく教えてください。
A: 私たちは、画像が他の画像と意味的にどれだけ密接に関連しているかに基づいて、画像をグループにクラスタリングしています。エッジケースとは、他のどの画像とも似ていない画像のことです。1つのグループか、数個のグループです。
Q: エッジケースに集中することで、大多数のパフォーマンスが低下することはないのでしょうか?
A: 本当にいい質問で、私たちも検討しているところです。私たちは、「一般的なケース」のデータを維持したまま、徐々にエッジケースを追加し、最適なモデル性能に達するタイミングを見ることを推奨しています。どの程度のエッジケースが、大多数のモデル性能の劣化を引き起こすようになるかは、それぞれのケースによって異なり、明確な最適数や割合はありません。
Q: エッジケースの分析が中心母集団をドリフトさせるかどうかを判断するために、エッジケースの飽和度を測る尺度はありますか?
A: これは現在Superb Curateの一部ではありませんが、私たちが取り組んでいることです。近々リリース予定の "モデル診断 "と "モデルモニタリング "機能は、この診断/モニタリングに役立ち、ユーザーは異なるトレーニングデータでパフォーマンスをテストするためにモデルを素早く反復できるようになります。
Q: Superb AIのユニークなセールスポイントはありますか?
A:
画像だけでなく、オブジェクトに対しても高品質な エンベッディングモデルを即座に提供(画像レベルのエンベッディングを提供する競合他社はいくつかありますが、通常1つのエンベッディングモデルしか使用しないため、当社と比較するとかなり低品質であり、オブジェクトデータに対しては提供されていません)。
独自のAuto-Curateアルゴリズムにより、様々なユーザーシナリオやニーズに基づいたワンクリックでのデータキュレーションを実現。
1つのプラットフォームでMLOpsサイクルを完結させるSuperb Label & Modelをスイートに提供。例えば、Superb Curateからキュレートされたトレーニング/検証セットを使ってSuperb Model上でモデルをトレーニングし、Superb Curate上でデータ中心的な方法でSuperb Model上でトレーニングされたモデルのパフォーマンスを診断することができます。
. Q: ビデオケースを試したことはありますか?
A: いい質問ですね。私たちはビデオケースについて少し実験してみました。どちらの種類のキュレーションも、サブセットを選択する必要がある多様なデータセットがあるときに、最も効果的に機能すると言えるでしょう。ビデオフレームを扱う場合、ビデオフレーム間の意味的な類似性が高くなりがちで、アルゴリズムが少し効きにくくなることがありますが、これはまだ実験中のことで、同様に、この種のテクニックがビデオから最も重要なフレームや特定のオブジェクトが存在するフレームを抽出するのに使えるかどうか、非常に興味があります。今までは画像データセットでの実験でしたが、これは間違いなく私たちが継続して取り組んでいることです。
Q: すべてを使用すると密度が高くなりすぎるため、散布図を視覚化するためにサンプリングしていると推測されます。サンプリングの場合、特定の方法を使用していますか、それともランダムですか?
A: エンベッディングベクトルの次元を2次元に減らすためにUMAPを使用します。我々のサンプリング方法は、クラスターを形成しない希少なエッジケースが散布図にうまく表現されるように、単なるランダムサンプリングよりも少し洗練されています。データをサンプリングするために、エンベッディング領域の情報を利用します。基本的には、埋め込み領域にXY座標(タイル)を描き、各タイルから均等にサンプリングすることで、2D投影がデータの実際の表現と一致するようにします。
Q: 多次元を2つから3つに減らすことで、さらに細かさが増すのでしょうか?
A: エンベディングの領域の実際の次元は~1024なので、それを2Dにしても3Dにしても、データのクラスタリングの具合という点では、あまり「技術的」な違いはありません。その上、3Dでパターンやクラスターを可視化するのは必ずしも容易ではないし、3Dで領域やクラスターをセグメント化するのはずっと難しくなります。
Q: ベースモデルは何ですか?製品で変更できるオプションはありますか?
A:エンベデッド/キュレーション・モデルは、CLIP、DINO、BEiTの組み合わせに基づいています。これらがどのように相互作用するかは、私たちの独自技術の一部です。 現在のところ、モデルは静的で、エンベッディングの計算には3つのモデルすべてが使用されます。将来的には、エンベッディングモデル(DINOv2やSAM)のアップグレードや追加、さらにはユーザーが独自のエンベッディングモデルを持ち込んだりアップロードできるようにする予定です。
Q: 誤ラベル付けされたデータを見つけるために使用される機械学習アルゴリズムは?
A:独自のアルゴリズムです。要するに、視覚的に似ている(埋め込みベクトルの値が似ている)にもかかわらず、異なるクラスタグが割り当てられているオブジェクトインスタンスは、ミスラベルである可能性が高いとみなされます。



