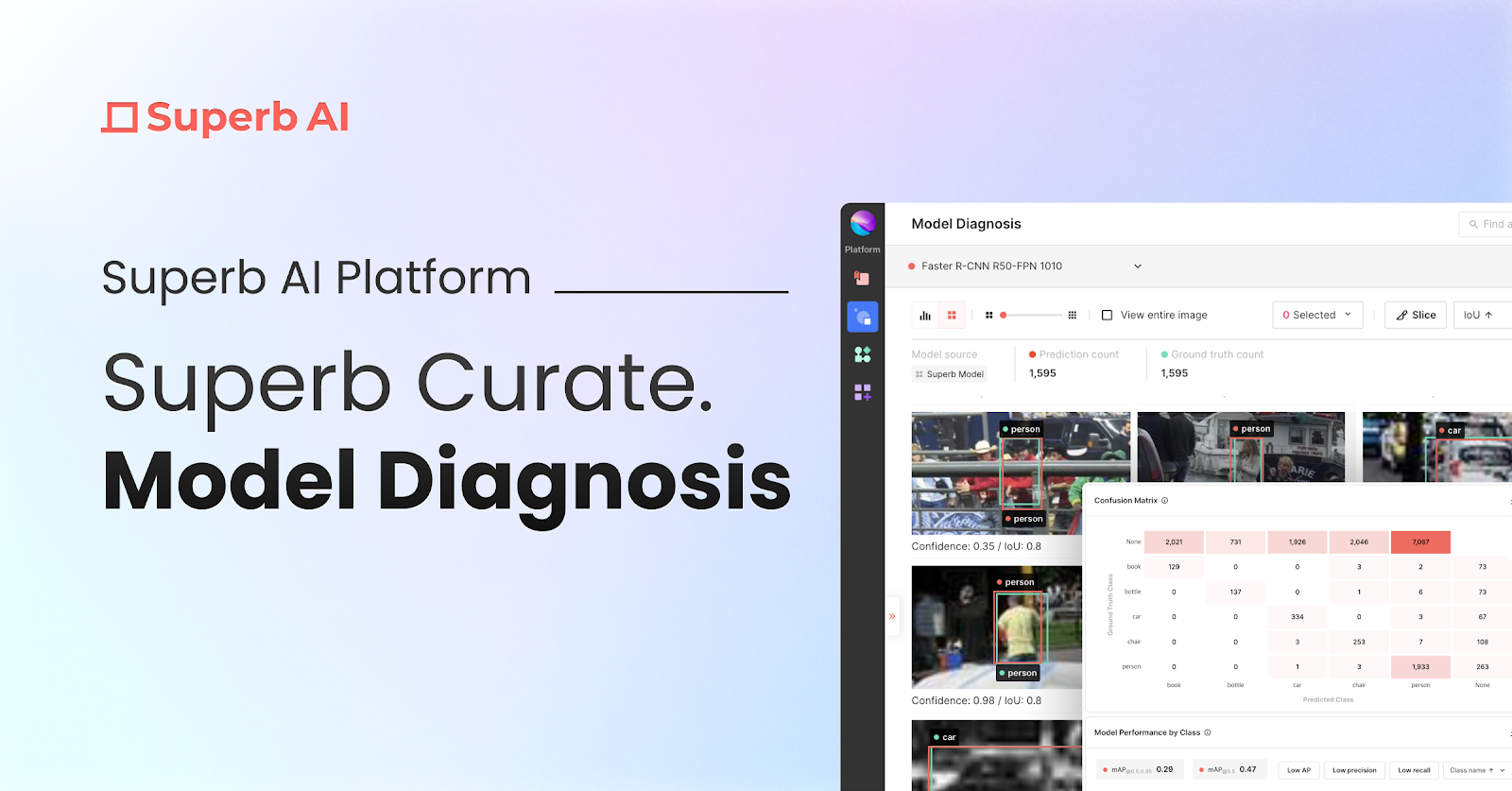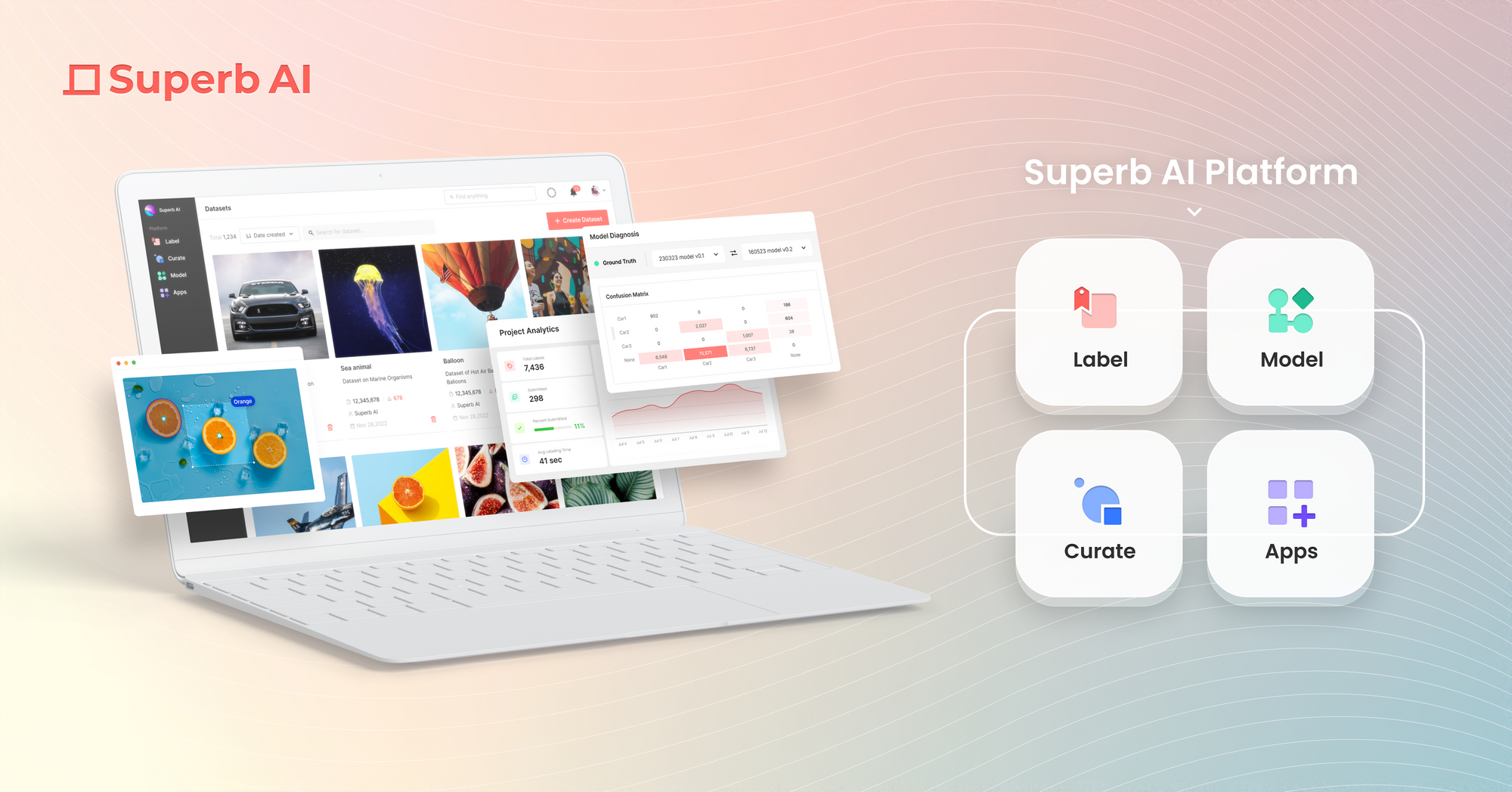
Curateについて
データは機械学習のバックボーンです。機械学習モデルは、正確かつ包括的で、よく整理されたデータがあって初めて効果的に学習できます。しかし、データの収集と管理には時間とコストがかかり、多くの場合、時間、資金、人的資源に多大な投資を必要とします。
Curateは、機械学習チームがデータのキュレーションプロセスを合理化し、より速く、より効率的に、より費用対効果の高いものにするために設計されています。Curateを使用すると、チームはトレーニングデータセットを分析し、クエリを使用してメタデータに基づいて検索し、2次元空間に埋め込まれたエンベッドを用いてデータセットの分布を視覚化することができます。
Curateは、機械学習チームがデータ・キュレーション・プロセスを最適化するための一連の機能を提供します。Curateを使用することで、チームは少ない学習データでラベル付けを行い、同等またはそれ以上のモデル性能を期待することができます。また、実環境にマッチした検証セットをキュレートすることで堅牢なモデルを構築し、大規模データを簡単にアップロードして、クエリ可能なメタデータで管理することができます。Curateと我々のエンベッディングを使えば、チームは独自のエンベッディングモデルを開発することなく、データをクラスタリングすることができます。
Curateは、機械学習チームがデータ・キュレーション・プロセスを最適化するための一連の機能を提供します。Curateを使用することで、チームは少ない学習データでラベル付けを行い、大量のデータを使用した時と同等またはそれ以上のモデル性能を期待することができます。また、実環境にマッチした検証セットをキュレートすることで堅牢なモデルを構築し、大規模データを簡単にアップロードして、クエリ可能なメタデータで管理することができます。Curateと我々のエンベッディングを使えば、チームは独自のエンベッディングモデルを開発することなく、データをクラスタリングすることができます。
Curateは、コンピュータビジョンアプリケーションのために大規模なデータセットをキュレートし、ラベル付けし、準備する必要がある機械学習チームのために設計されています。Curateの特徴と機能は、選択バイアス、クラス不均衡、異常値検出など、機械学習者が直面する最も一般的なデータ問題を克服するのに役立ちます。Curateを使用することで、チームはトレーニングデータセットが包括的で、正確で、バランスが取れていることを確認することができ、より効果的な機械学習モデルとより良いビジネス成果につながります。
手作業によるデータキュレーションが苦痛な理由
データのキュレーションは機械学習に不可欠な要素ですが、時間とコストのかかるプロセスです。手作業によるキュレーションは、エラーやバイアスが発生しやすく、常に骨の折れる作業となります。これは、効果的なトレーニングのために大規模なデータセットが必要とされ、データの品質が機械学習モデルの性能に大きな影響を与えるコンピュータビジョンのアプリケーションに特に当てはまります。
手作業によるデータキュレーションの主な悩みの1つは、機械学習モデルを効果的に学習させることができる、価値の高いデータのサブセットを選択する必要性です。この複雑なタスクは、データの希少性、ラベルノイズ、クラスバランス、特徴バランスなどの様々な要因を注意深く考慮する必要があります。自動化されたキュレーション機能がなければ、機械学習チームは、時間がかかり、エラーが発生しやすく、拡張が困難な手動選択プロセスに頼らざるを得ません。次のセクションでは、チームのデータキュレーションプロセスを自動化し、機械学習チームにより効率的で正確、かつスケーラブルなソリューションを提供する、当社のオートキュレート機能を紹介します。
コンピュータビジョンのための自動キュレーションについて
Auto-Curateは、機械学習チームのデータ・キュレーション・プロセスを自動化する新しいCurate製品の機能です。これは、AIが画像間の視覚的類似性を理解し比較することを可能にする「エンベッディング」と呼ばれるAI技術に基づいています。エンベッディングは、画像クラスタリング、類似検索、推薦システムなど、多くのコンピュータビジョン・アプリケーションに力を与える基礎技術です。
Auto-Curateは、価値の高いデータのサブセットを選択するために、4つのキュレーション基準(データの疎性(希薄性)、ラベルノイズ、クラスバランス、特徴バランス)を考慮します。
疎性(スパースネス)とは、埋め込み空間におけるデータの希少性のことです。Auto-Curateは、埋め込み空間上で希少な位置にあるデータ、あるいはデータセット内で希少なデータを選択します。例えば、ある特定の種類の画像がデータセット中に一度しか出現しない場合、Auto-Curateはそれを希少なデータポイントとして選択することがあります。
ラベルノイズとは、誤ラベル付けされる可能性の高いデータや、埋め込み空間内で近傍に位置するがクラスが異なるデータ点を指すします。Auto-Curateは、正しくラベル付けされ、同じクラスの他のデータ点と類似している可能性の高いデータを選択します。
クラス・バランスは、歪んだクラス分布に対処するのに役立ち、頻度の高いクラスをアンダー・サンプルし、頻度の低いクラスをオーバー・サンプルすることができます。例えば、あるデータセットが他のクラスよりも頻繁に出現するクラス分布を持っているとします。このような場合、Auto-Curateは頻度の低いクラスからより多くのデータを選択し、分布のバランスを取ることができます。
特徴バランスは、各画像のメタデータや属性の重要性を考慮し、埋め込み空間において均等にデータをサンプリングします。例えば、ある属性が機械学習モデルにとって非常に重要であるとします。その場合、Auto-Curateはその属性を持つデータ点をより多く選択し、データセットにその属性が十分に反映されるようにします。
Auto-Curateを使用すると、均一な分布でデータの冗長性を最小限に抑えたラベルなし画像のデータセットを簡単にキュレートすることができます。また、希少な画像やエッジケースの可能性が高い画像のみをキュレートしたり、データセットを代表し、頻繁に出現する画像のみをキュレートすることもできます。Auto-Curate機能は、キュレーションの手作業を減らし、機械学習チームが正確でよくキュレーションされたデータセットでより効果的なモデルを構築できるようにします。
検証結果の例 :MNISTデータセットへのオートキュレートの適用
MNIST データセットについて
MNISTデータセットは、機械学習モデルの訓練とテストに使用されるコンピュータビジョンデータセットの典型的な例です。このデータセットには、0から9までの手書き数字の画像が7万枚含まれており、各画像のサイズは28×28ピクセルである。その小さなサイズと単純な分類タスクにもかかわらず、MNISTデータセットは、機械学習モデルのベンチマークとして、今でも業界で広く使用されています。
エンベッドを使ったデータセット分布の分析
Auto-Curateを使用する最初のステップの1つは、エンベッディングを使用してデータセットの分布を分析することです。エンベッディングは、画像間の視覚的類似性を理解するための強力なツールです。エンベッディングは画像を高次元空間のベクトルとして符号化し、類似画像は近くに、非類似画像は遠くに配置されます。
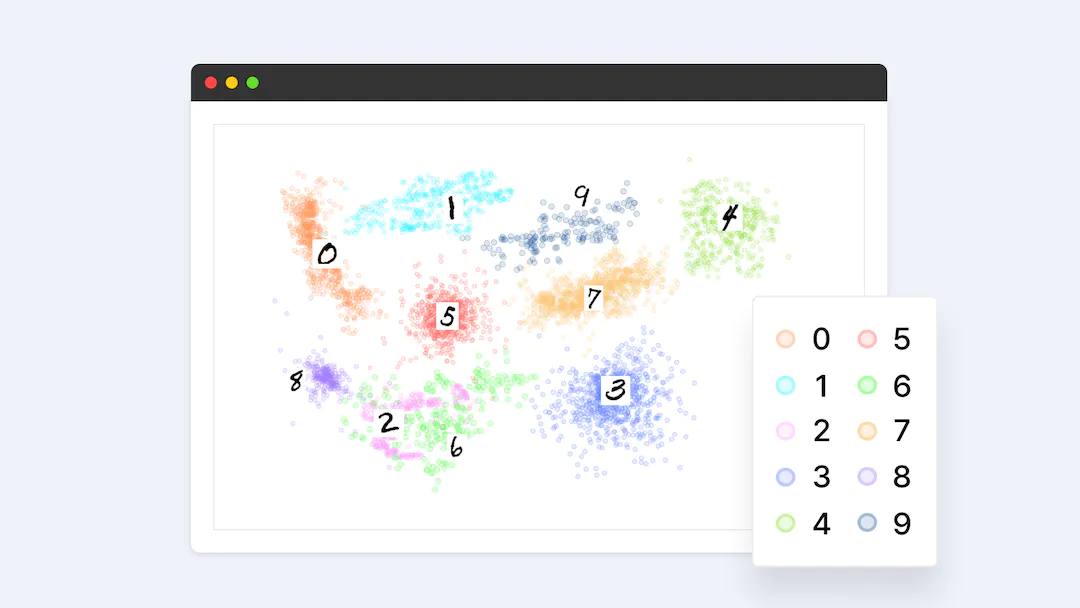
MNISTデータセットの分布を解析するために、BEiT埋め込みモデルを用いて、データセットの各画像の埋め込みベクトルを連結し、t-SNEを用いて2次元空間にプロットします。これにより、データセットの分布を散布図で可視化することができる。ここで、各点は画像を表し、色は桁のラベルを示します。
MNISTデータセットの埋め込み可視化。各点は画像を表し、点の色は各画像が10桁のクラスのどれに属するかを表す。

MNISTデータセットの埋め込み可視化。約10,000枚の画像をサンプリングし、画像のサムネイルを可視化。

MNISTデータセットの2次元エンベッディング値の散布図を分析すると、画像がクラスラベルに基づいて明確なクラスタにグループ化されていることがすぐにわかります。 同じクラスに属する画像は、2次元平面上で近くに位置する傾向があり、エンベッド値が類似していることを示します。これは、画像のエンベッディングが、背景、色、構図、角度などの画像間の視覚的類似性を捉えるように設計されていることによります。その結果、視覚的に類似した画像は、類似したエンベッディング値を持ち、二次元平面上でより近くに位置します。
これらのクラスタに加え、2つ以上のクラスタの間の領域に位置する画像も存在します。これらの画像は、複数のクラスと視覚的な類似性を共有しているため、1つのクラスに分類することが困難なケースを表しています。これらの画像は、機械学習モデルを学習する際の貴重なデータポイントであり、モデルが正しく予測することが困難なエッジケースを表しています。これらの画像を学習セットに含めることで、機械学習モデルは、稀なコーナーケースを予測・検出できるように、より堅牢な学習をすることができ、精度とパフォーマンスが向上します。
全体として、MNISTデータセットの2次元エンベッディング値の散布図は、画像間の視覚的類似性に関する貴重な洞察を提供し、最適な機械学習モデルの性能を得るためにエッジケースを学習セットに含めることの重要性を明示しています。
Auto-Curateによるトレーニングセットの選択
データセットの分布を分析した後、Auto-Curateを使用して、学習と検証のために価値の高いデータのサブセットを選択することができます。Auto-Curateアルゴリズムが開始されると、システムはまず類似性に基づいて埋め込みデータをクラスタリングし、次に各クラスタを代表する画像を選択します。初期トレーニングセットのキュレーションのために、アノテーションされた「クラス」と埋め込み値の両方においてバランスの取れたデータセットを作成することは、良いプラクティスであると考えます。また、この初期段階では、モデルの学習を狂わせる可能性があるため、あまり多くのエッジケースを含めることはお勧めしません。したがって、選択されたトレーニングデータセットは、データセット全体を代表するサブセットであり、初期の機械学習モデルのトレーニングに有用です。
以下のMNISTの例では、学習用に1,000枚の画像のサブセットを自動キュレーションしました。選択された部分集合は、桁の分布が均等で、データの冗長性が最小です。これは、選択された部分集合が全ての数字の代表的なサンプルを含み、部分集合の中に類似した画像が多すぎることを避け、また学習が困難な希少なエッジケースを選択しすぎることを避けることを意味します。

Auto-Curateによるエッジケースサンプルの選択
Auto-Curateは、トレーニングおよび検証用の代表的なデータサブセットの選択に加えて、データセット内で稀なエッジケースサンプルの選択にも使用できます。これらのレアサンプルは、モデルにとって学習が困難で、しばしば誤った結果予測を行い、精度を低下させる画像です。これらのサンプルをキュレートすることで、ユーザーはモデルをさらに訓練し、エッジケース・シナリオに対してより堅牢にすることができます。これは、モデルが現実世界でうまく機能するために非常に重要なことであります。
Auto-Curateでエッジケースのサンプルを選択するために、我々はキュレーションアルゴリズムを「疎密」基準をより重視するように設定します。つまり、アルゴリズムは、エンベッディング・スペ ースにおける他のデータポイントから離れているケースを選択します。これは エンベッドスペース上で稀な位置にある画像や、エッジケースである可能性が高い画像を選択するということになります。
選択されたDigit 4とDigit 7クラスの画像例。これらの画像はスパース性(疎性)が高く、まれなエッジケースを表している。

不確実性の高いまばらなクラスター

機械学習モデルが実世界のデータで正確な予測を行えるようにするためには、稀なエッジケースを訓練セットと検証セットに含めることが極めて重要です。なぜなら、これらのエッジケースは、その希少性ゆえにモデルが正しい予測を行うことが困難な場合が多いからです。しかし、エッジケースを多く含みすぎるとオーバーフィッティングにつながる可能性があるため、十分なエッジケースを含み、モデルに負荷をかけすぎないようにバランスを取ることが重要です。
データセットからこのようなレアなエッジケースを選択するために、CurateのAuto-Curate機能は、エンベッドに基づくAIベースのキュレーションアルゴリズムを使用します。このアルゴリズムは、エンベッディングスペースにまばらに配置されているデータポイントや、データセット内で希少なデータポイントを選択します。このようなデータポイントはモデルの学習が困難であり、モデル導入時に誤分類されることが多い。これらのデータ点を訓練セットと検証セットに含めることで、モデルはこれらの稀なケースをより適切に予測・分類できるように学習することができます。
稀なエッジケースを含めることは重要ですが、データセットに十分な数の一般的なケースの例を含めることも重要です。こうすることで、モデルが予測を構築するための強固な基盤を確保することができます。希少なエッジケースを訓練セットと検証セットに含めることで、機械学習モデルは、実世界のデータで予測を行う際に、より堅牢で正確なものになります。
Auto-Curateによるラベル付けミスデータの処理
Auto-Curateを使用する際の注意点として、データセットが完全にラベル付けされていない場合、エッジケースのキュレーションの結果にラベル付けミスのデータが含まれることがあります。これは、モデルが全てのラベルをグランド・トゥルースまたは完全にラベル付けされたものと見なすことを考えると、ある桁が別の桁としてラベル付けされているようなラベル付けミスのケースは、Auto-Curateアルゴリズムにとって「レアケース」と見なされるためです。このようなミスラベルのケースは、エンベッディングスペースの散布図において、真のラベルのクラスタから遠く離れているため、容易に見つけることができます。
オートキュレートでミスラベルのデータを扱うには、ラベルノイズ基準を使用することができます。この基準は、あるデータポイントが異なるラベルを持つ他のデータポイントの近くにある場合、そのデータ点は誤ってラベル付けされている可能性が高いという仮定に基づいています。これらのデータポイントを選択することで、ユーザーは簡単かつ迅速にラベリングエラーを修正し、トレーニングセットに追加することができる。エッジケース・サンプルを選択してさらに学習を進めることで、ユーザーは機械学習モデルのパフォーマンスと堅牢性を向上させることができます。
誤ラベルの可能性が比較的高いエッジケース画像の例

データを調べると、"6 "や "9 "と分類されたエッジケースの画像の中には、誤ったラベルが貼られているものがあることがわかります。人間が正しいラベルを識別できる場合もあれば、難しい場合もあります。このような場合、ユーザは特定のユースケースやデータ要件に応じて、正しいラベルで画像を再分類するか、トレーニングセットから完全に削除することを選択できます。このような誤ったラベルのケースは、将来、そのようなケースを識別するために、より堅牢で正確な機械学習モデルをさらに訓練するために使用することもできます。
Curateによる機械学習モデルの精度向上
CurateのAuto-Curate機能は、機械学習モデルの精度とロバスト性を向上させるために弊社製品が提供する数多くのツールの1つに過ぎません。データセットの分布分析、エッジケースのキュレーション、ラベルノイズの補正など、AIベースの強力なデータキュレーション機能により、Curateは機械学習チームのトレーニングデータセットのキュレーションをより簡単かつ効率的にします。
Curateについて、またMLモデルの最適化にどのように役立つのか、さらに詳しくお知りになりたい方は、ぜひ私たちのチームにご連絡ください!