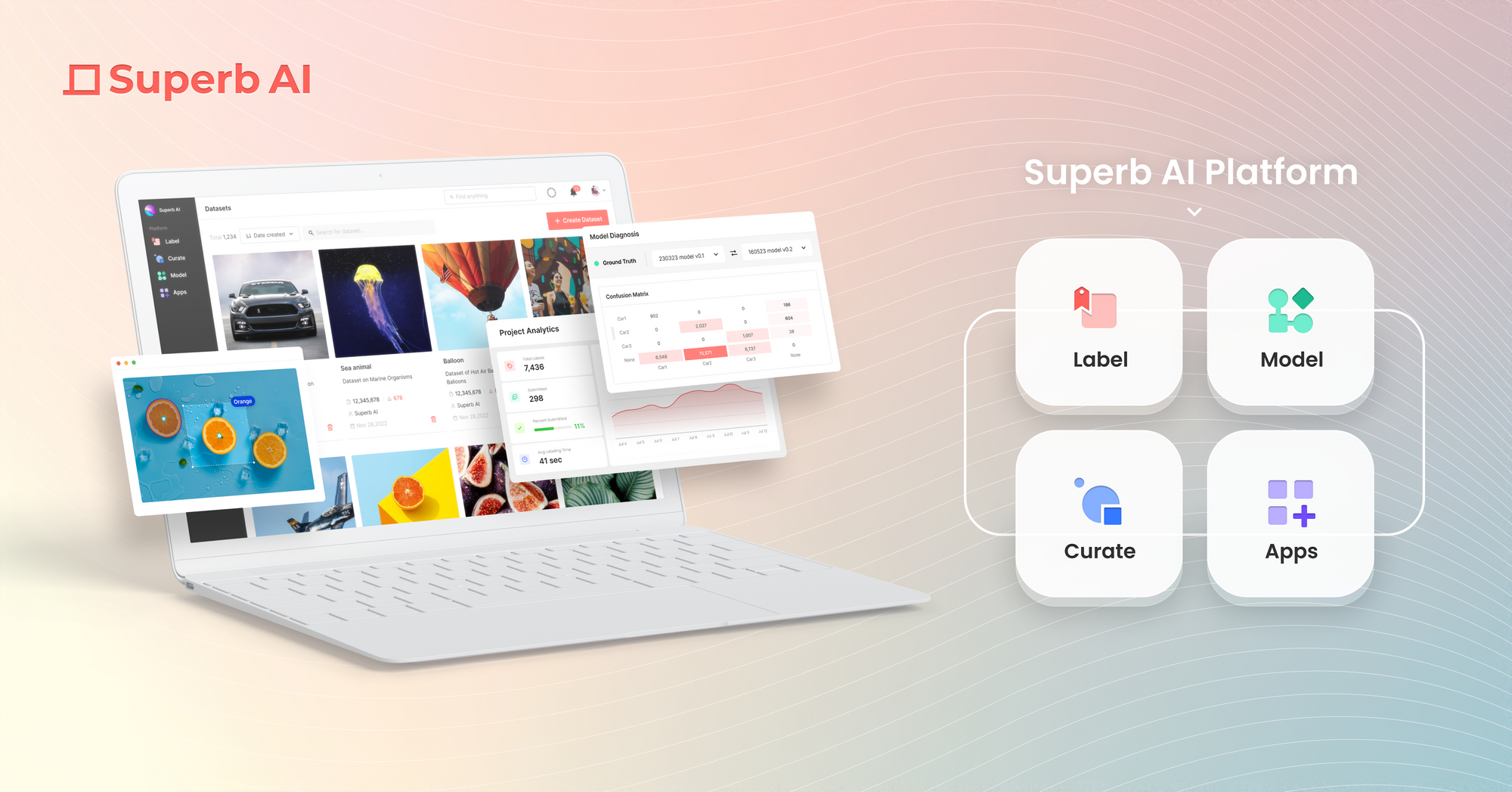
コンピュータビジョンのためのデータをキュレーションする際にチームが直面する最大の課題の1つは、手作業、ランダムサンプリング、自動キュレーションのような自動化されたアプローチを問わず、選択したデータがモデルのトレーニングや検証に適しているかどうかを評価することです。これは主に、選択されたオブジェクトの多様性、希少なオブジェクトや珍しいオブジェクトが十分に含まれているか、誤ったラベル付けのインスタンスがあるか(またはないか)に基づいています。
6月、Superb Curateのいくつかの重要なアップデートをリリースし、画像やオブジェクトの埋め込みの散布図を「クール」から「マスト」に変えました。また、グリッドタブと散布図タブに新しいビューと機能を追加し、オブジェクトごとにデータを検査できるようになりました。
Superb Curateの最新機能と性能については、こちらをお読みください。
散布図を使って簡単にデータを探索し、セグメント化できます。

散布図上で直接データを照会
選択したデータからスライスを作成(サンプリングデータとその領域に対応するデータを含む
スライスまたはクエリー結果の散布図を見る

散布図上の点とサムネイルを切り替える
散布図で作業するとき、そして一般的にデータをキュレーションするとき、データがデータセットの他の部分と関連してどのように分布しているかを完全に理解することは非常に重要です。そのために、以下の機能を追加しました:
クエリ結果を特定のスライスまたはデータセット全体で比較できます。
スライスに含まれるデータを完全なデータセットと比較する。
新しいオブジェクト・レベルのグリッド・ビューと散布図ビューを使用して、データを検査します。
このリリース以前は、チームは画像レベルでのみデータの検査やクエリを行うことができました。オブジェクトレベルのビューが追加されたことで、チームは画像内の対象オブジェクトの正確な位置を素早く特定し、そのオブジェクトがどのような特徴を持っているか、どのようにクラスタ化されているかなどを一目で把握できるようになりました。
Object-Based Queries

Grid View

「自動車」や「人」などのオブジェクトクラス
「オクルージョン(遮蔽)」や「トランケーション(部分一致などの検索)」などのアノテーションのメタデータ
「バウンディングボックス」のみを表示するなどのアノテーションタイプ
これらのフィルターをクエリーと組み合わせることで、データセットを必要なだけ深く掘り下げることができ、「干し草の山の中の針」をこれまで以上に簡単に見つけることができます。
Scatter View

散布図により、チームはデータセットの分布をオブジェクトごとに表示できるようになりました。クエリやスライスなどの新しい散布図機能も、オブジェクトレベルの散布図ビューでサポートされています。
キュレートの今後は?
カスタムオートラベルやオートキュレーションのようなツールを使って、少ない時間とはいえ、データを綿密にラベル付けし、キュレーションするために費やした時間を想像してみてください。モデルをトレーニングまたは検証するためにデータをエクスポートし、最終的にプロトタイプとして、あるいは本番でその成功を目の当たりにしたときの勝利感を思い浮かべてください。
しかし、勝利の霧が消えても、疑問は消えません。"どうすればモデルをさらに微調整できるのか?"、"どうすればミスラベルやバイアスといった長引くデータの問題を修正できるのか?"。従来通りに、次のステップは試行錯誤のほぼ終わりのないサイクルを伴います。
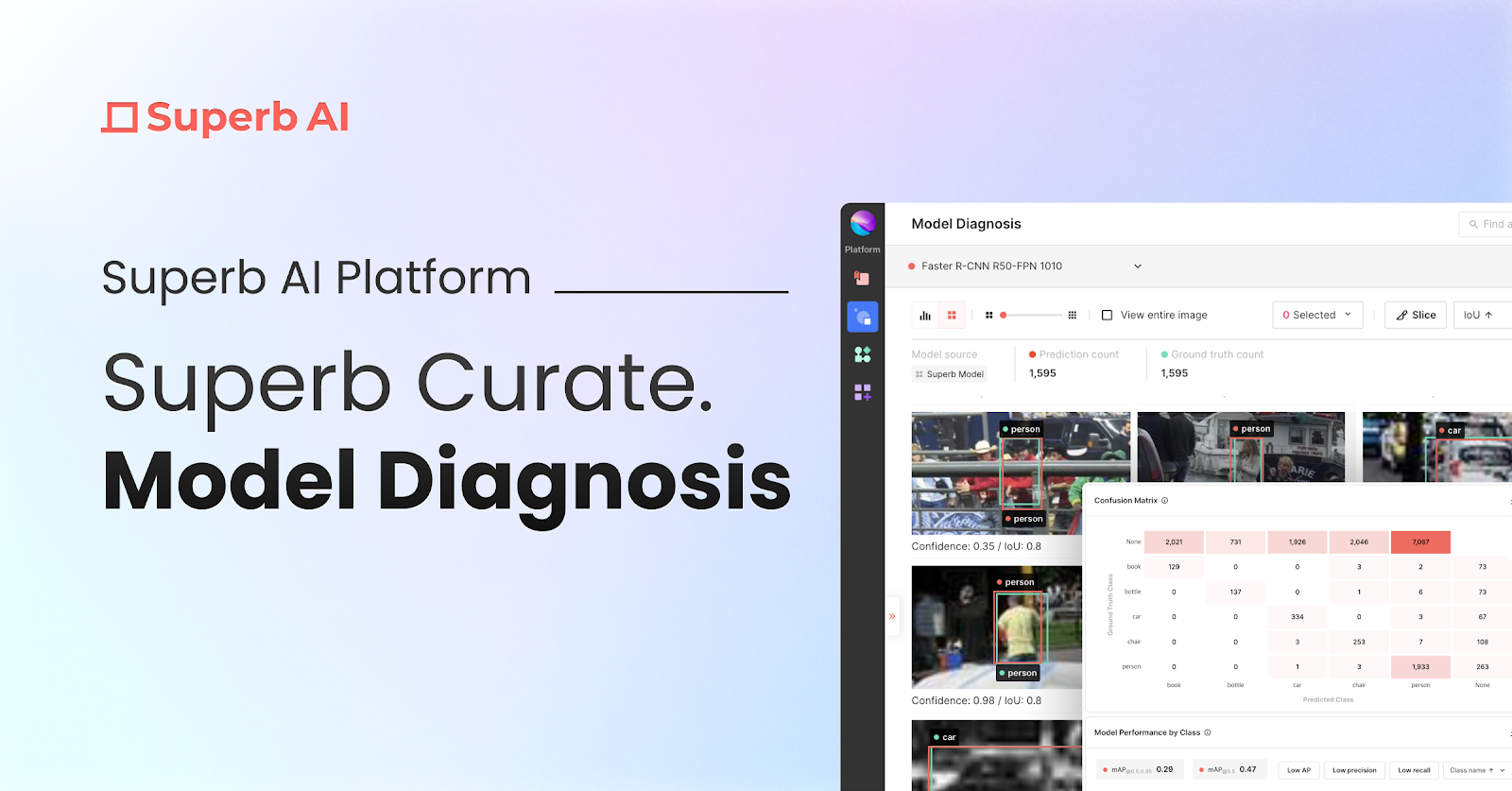
しかし、私たちはこのような頭痛の種となる試行をなくすために取り組んでいます。まもなく、モデル診断を通じて、完全にデータ中心的な方法でモデルのパフォーマンスと脆弱性を評価できるようになります。
今後のリリースでは、学習させたモデルがどのようなタイプのデータで良い結果を出すか、あるいは悪い結果を出すか、そしてそれを修正・改善するためにどのようなアクションを取るべきかを理解するために必要なすべてを提供します。また、同じデータ(または同じモデルの2つのバージョン)に対してトレーニングされた異なるモデルのパフォーマンスを比較対照する方法も含まれます。
7月には詳細が発表されるのでお楽しみに!