機械学習の世界はデータを大量に必要とします。特にコンピューター・ビジョンのタスクでは、データが多ければ多いほど優れたモデルになることが多い。しかし、すべてのデータセットが同じように作られているわけではない。特に頻度が低かったり、稀であったりする特定のケースでは、データが不足することがあります。このような場合、データ補強技術がモデルの性能に大きな影響を与えます。
堅牢かつ信頼性の高いコンピュータ・ビジョンモデルを構築するためには、これらの課題にどのようにアプローチし、管理するかをよく理解することが鍵となります。しかし、具体的にどのようにしてこの複雑な海を乗り越えることができるのでしょうか?その答えの一端は、Superb CurateとそのAuto-Curate機能のようなツールにあります。
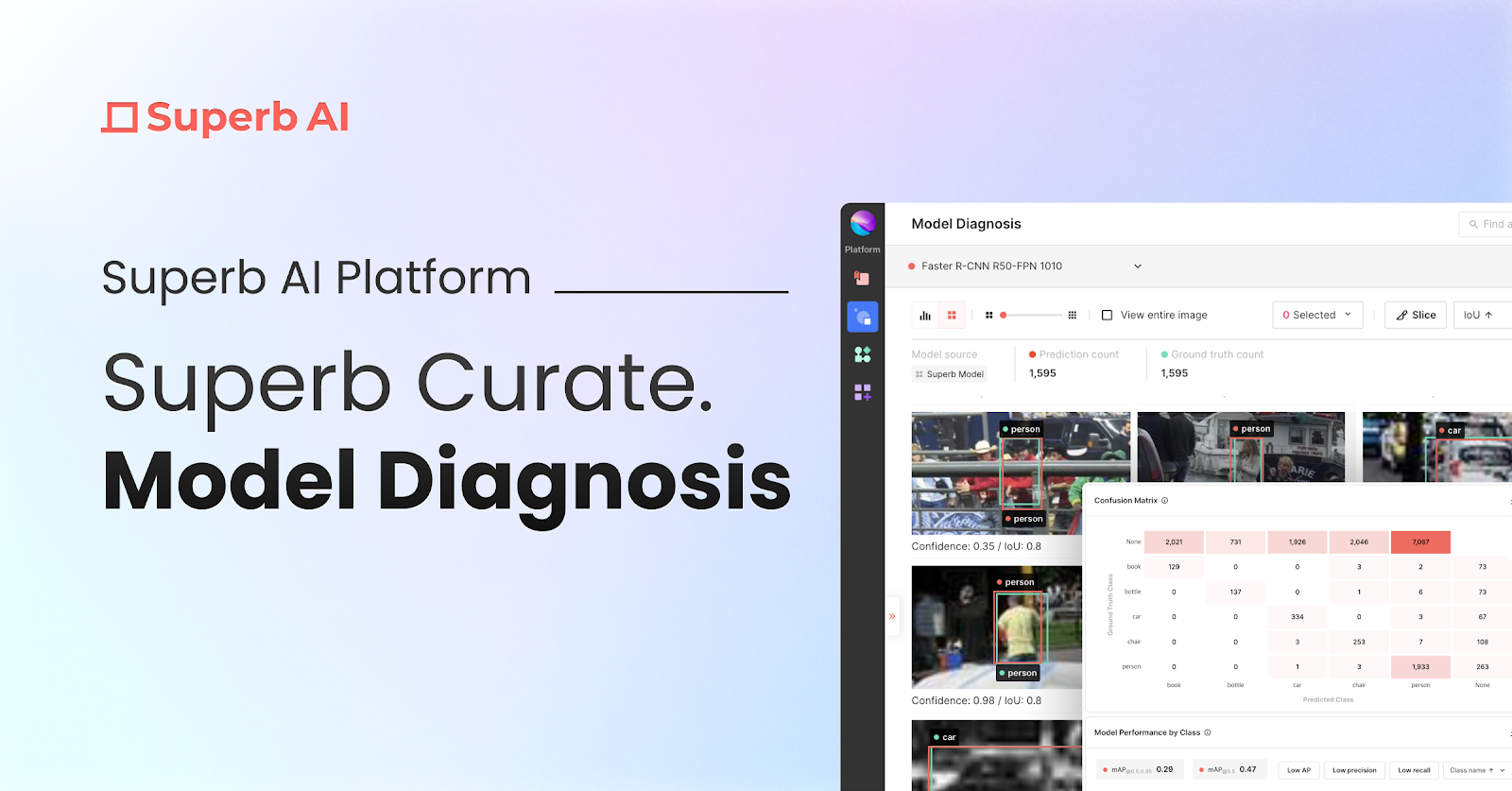
モデル構築の複雑さをより深く知りたい方は、関連記事もお読みください。モデル「モデル診断がデータ問題の早期発見に役立つ方法」では、データセットの問題を早期かつ正確に特定することで、いかに時間を節約し、効率を向上させ、最終的に予測性能の向上につながるかを明らかにしています。これらの診断テクニックを理解することは、問題を未然に防ぎ、モデルが最初からクリーンで高品質なデータでトレーニングされていることを保証する上で非常に貴重です。
さらに、「精度のためのキュレーション:バランスのとれたコンピュータビジョンデータセットの構築」という記事では、バランスの取れたデータセットを構築するための実践的な戦略を紹介しています。この記事では、表現力を確保し、偏りを減らし、コンピュータビジョンモデルの精度を向上させる方法でデータをキュレートする方法について包括的なガイドを提供します。
内容について
不均衡なデータセットの課題
Superb Curateとクラスおよびシナリオの不均衡への取り組み
オーグメンテーションによる根本的なデータ不均衡の解決
従来のオーグメンテーション技術と高度なオーグメンテーション技術
事例
結論
データ収集の難しさ
データはコンピュータ・ビジョン・システムの生命線です。この分野でよく使われる格言に "より多くのデータ、より良いパフォーマンス "があります。一般的には正しいが、この言葉に注意が必要です。
特に不均衡なデータセットを扱う場合、大量のデータを収集することは万能とは言えません。さらに、データ収集の現実は、特に必要とされるデータが少なかったり、入手が困難であったりする場合、見た目よりも一筋縄ではいかないことが多く見受けられます。
まれなケースが発生した場合
「レアケース」または「エッジケース」は、データセット中で発生頻度の低いシナリオやクラスを表しています。例えば、医療データセットにおけるまれな病気や、画像認識データセットにおけるめったに見られない物体などです。このような場合、これらのケースの希少性や、これらのデータポイントをキャプチャすることに関連する困難さのために、単純に多くのデータを収集することは実行不可能かもしれません。
データセットの不均衡と品質の追求
より多くのデータを収集できたとしても、必ずしもバランスのとれたデータセットになるとは限りません。さらに、単にデータセットのサイズを増やすだけでは、必ずしも実行可能で効果的な解決策とはなりません。
より多くのデータの必要性は、収集したデータの質と多様性も考慮しなければなりません。例えば、追加で収集したデータがすでにデータセットに存在するものと類似しすぎている場合、特定の特性やパターンに合わせすぎてしまい、モデルの一般化能力が妨げられる可能性があります。

不均衡に対するバランスの取れたアプローチ
データの不均衡に対処する際には、特にまれなケースについては、より慎重なアプローチが必要となります。そこで登場するのがデータ補強です。
より多くのデータを蓄積することだけに集中するのではなく、データ増強技術によって既存のデータを強化し、より多様でバランスのとれたデータセットを生成することが可能となります。このアプローチは、特にデータ収集が困難な状況において、モデル性能の向上につながります。
バランスのとれたデータセット作成の推進
効果的で偏りのない機械学習モデルの作成は、非常に困難な作業です。データの正確性、包括性、整理性を確保するために、綿密なキュレーション、ラベリング、分割が必要となります。しかし、膨大な量のデータ、手作業による取り扱い、関連するコストが、この作業を複雑で時間のかかるものにしているのです。
SuperbのAIを搭載したソリューション、Curateは、このようなシナリオを解決します。Curateは、MLチームがどのような状況でも最も重要なデータを特定し、ラベル付けし、活用できるようにします。Curateは、コンピュータビジョンにおける最も重要な課題の1つである、価値のあるデータとそれ以外を選別すること、選択バイアスやクラスの不均衡を回避すること、「悪い」データと有用なエッジケースを区別することに取り組んでいます。
Ready to get started with Superb Curate?
Curateのエンベッディングベースキュレーション機能でモデルのパフォーマンスを向上
スケーリングの苦労
ほとんどのチームは関連するデータを視覚的に特定することができますが、何万ものデータポイントを手作業でレビューする作業は、ほとんどの組織にとってスケーラブルでも実現可能でもありません。また、この方法は、ラベリングするデータの優先順位をつける体系的な方法を提供しないし、冗長性を最小限に抑えたバランスの取れたサンプルの分布も保証しません。
データ取得段階で体系的なメタデータの設計と収集が行われないため、手作業による検索とレビューがさらに困難になります。注釈のないデータを検索することができないため、多くのチームは「多ければ多いほどよい」というアプローチを採用するが、これはモデルの性能とデータ準備コストの点で収穫が少なくなることが往々にして起きます。
Curate: キュレーションの自動化
Curateは、大規模なデータの検索、管理、可視化を簡単に行う方法を提供することで、この課題を解決します。キュレーションプロセスを自動化することで、多大な計算コストやインフラコストを回避することができます。
この自動化により、MLチームは、どのデータにラベルを付けるべきかを特定し、実際の展開データを反映したデータ分布を作成し、バランスの取れた訓練セットと検証セットを生成し、外れ値や異常を簡単に検出することができるようになります。
データキュレーションと管理ワークフローから、一貫性がなくコストのかかる人的要素を排除することで、Curateは組織のコンピュータビジョンプロジェクトのコスト削減を支援します。このコスト削減にはラベリングも含まれるため、投資収益率が向上します。

自動キュレーションについて
Superb Curateは、データセットまたはスライスレベルで、お客様のモデル要件に最適なデータセットを自動的にキュレートする機能を提供します。Auto-Curateと名付けられたこの機能は、データを分類・キュレートする際に、データの希少性、ラベルノイズ、クラスバランス、特徴バランスを考慮します。
Auto-Curateは、キュレーションのコストを削減し、より正確でよくキュレーションされたデータセットによる高性能モデルの作成を可能にします。Curateは、いくつかの自動キュレーション手法を提供しています:
どのデータをラベリング対象とするか: 最初にラベルを付けるべき最も重要なデータポイントを特定します。
バランスの取れたスライスの作成: データセット全体が適切に扱われていることを保証します。
学習セットと検証セットの分割: ラベル付きデータセットを自動的に分割し、偏りのないモデル検証を保証します。
エッジケースの検出: まばらに配置されたデータポイントを特定し、あらゆるシナリオでロバスト性とパフォーマンスを保証します。
ラベリング間違いの特定: 誤ラベルの可能性が高いデータポイントを特定し、高品質のラベル付きデータセットを確保します。
自動化されたデータキュレーションにより、モデルのパフォーマンスを向上。
データ補強: 実践的なシナリオ
データ増強についてさらに理解するために、機械学習において、異なる種類の犬を分類するモデルを構築するシナリオを考えてみましょう。データセットにはほとんどの犬種の画像が豊富に含まれているが、特定の犬種、例えばパグに関しては不足しているとする。 その結果、利用可能なデータが少ないため、パグを正確に分類するモデルの能力はかなり低下してしまいます。
このような状況では、データの増強が解決策となります。より多くのパグの画像を追加することで、本物の画像であれ、合成的に生成された画像であれ、あるいは既存の画像を操作すること(例えば、独自のインスタンスを作成するために複製したり歪ませたりすること)であれ、この存在感の薄い品種を正しく分類するモデルの能力を向上させることができます。
このようなデータ補強プロセスによってデータセットの多様性と量が増加すると、機械学習アルゴリズムのパフォーマンスが向上します。追加されるデータは画像からテキストまで様々であり、データ補強は様々なデータタイプや機械学習タスクに適用可能な汎用性の高い方法となっています。
データ補強はモデルの精度を向上させるのでしょうか?ほとんどの場合、答えはイエスです。データ補強技術は一貫して、モデルの精度を高める能力を実証してきました。モデルが学習データにオーバーフィットする傾向を低減することで、モデルの汎化能力を向上させ、未経験のデータや新しいデータに対してより良いパフォーマンスをもたらします。
限定的で不均衡なデータとの戦い
データ補強は、データセットの中で希少なケースや十分に代表されていないケースを扱う場合に特に価値を発揮します。この機能は、限られたデータや不均衡なデータの問題に対する強力な武器となり、最終的には、困難なシナリオであっても、より正確で信頼性の高い結果を提供できるモデルを実現します。
データ補強の課題
機械学習におけるデータ補強の利点が証明されているにもかかわらず、特にデータセットにおけるクラスやシナリオの不均衡に対処する場合、重大なハードルとなる課題が存在します。これらの問題は、単に多くのデータを収集するだけでは解決できないことが多い。
オリジナル情報の保存の難しさ: 画像補強のプロセスでは、重要な情報が変更されたり失われたりするリスクが常に存在します。例えば、画像を過度に回転させたり、拡大縮小したりすると、認識できなくなったり、目の前のタスクと無関係になったりします。
不自然なデータインスタンスの生成: データ補強法は、実際のカテゴリーやクラスを代表しないインスタンスを生成する可能性があり、非現実的な結果につながります。
データの不均衡の解消: オリジナルのデータセットにおける深刻な不均衡に対処するには、単純な補強技術では不十分な場合があります。GANや合成データ生成のような、より複雑な技術が必要になるかもしれませんが、これには独自の課題が伴います。
拡張されたデータへのオーバーフィット: 適用された補強の種類にモデルが過剰に適合してしまい、未知のデータへの汎化能力が制限される危険性がある。
演算コスト: GANやスタイルトランスファーのような高度な拡張技術は計算集約的で、かなりのリソースと時間を必要とします。
バイアスの管理: 補強プロセスは、元のデータに存在するバイアスを不注意に導入したり、悪化させたりする可能性があり、これは不均衡の場合に特に不利になる可能性があります。
実際の使用例と使用事例
データ補強は、機械学習モデルのパフォーマンスを向上させる上で極めて重要な役割を果たし、様々な分野でゲームチェンジャーとなることが証明されています。
これは、データが乏しかったり、バランスが悪かったり、稀な事例が多い場合に特に当てはまります。業界別のケーススタディは、データ増強の広範な影響力と重要性を強調しています。
ヘルスケア: 疾病診断
医療業界は、特にアルカプトン尿症のような希少疾患の場合、データの不足に悩まされることが多い。ある研究チームは、ディープラーニングモデルによってこの遺伝性疾患の早期発見を強化しようとしました。しかし、この病気に関連する画像は限られており、学習プロセスが複雑でした。
この問題に対処するため、彼らは利用可能な画像の回転、反転、ズームなどのデータ増強技術を採用し、モデルが学習するためのより多くのデータを作成しました。 これらの方法以外にも、彼らはSuperb CurateのAuto-Curate機能のようなツールの使用も検討しました。Auto-Curate機能は、データセット全体またはデータのカスタマイズされたスライスに対して、特定のニーズに応じてデータをキュレートするための堅牢で自動化された方法を提供します。
アルカプトン尿症の診断の文脈では、Auto-Curateの「Curate What to Label」オプションは、データのばらつき、ラベルノイズ、クラスバランス、特徴バランスなどの要因に基づいて、どの未ラベルデータに最初にラベルを付けるべきかの優先順位を研究者たちに導くことができます。ラベル付け後、「Split Train/Validation Set」オプションは、データセットをトレーニングセットと検証セットに分割し、モデルの汎化性能を向上させ、オーバーフィッティングを回避するのに役立ちます。
Find Edge Cases'オプションは、データセット中の疾患の稀な事例を特定するのに役立ち、モデルの精度と多様性を向上させる。さらに、'Find Mislabels'は、モデルの信頼性に影響を与える可能性のあるラベリングエラーを特定し、修正するために使用することができます。

自動車: 自動運転
自動車業界では、ウェイモのような企業が「レア・シナリオ・シミュレーション」と呼ばれる手法を活用し、エッジケースとなる運転シナリオのバリエーションを数多く作成しています。この方法は効果的ではあるが、Superb CurateのAuto-Curate機能のようなツールを使えば、さらに強化することが可能です。
Auto-Curateは、モデルの汎化能力を向上させ、オーバーフィッティングを回避する上で極めて重要な、バランスの取れたトレーニングセットと検証セットの作成に役立ちます。また、エッジケースを識別し、トレーニングデータセットに組み込むことで、モデルの精度を飛躍的に向上させることができます。
小売業: 商品分類のための画像認識
小売業では、画像に基づく商品分類などのタスクに機械学習が広く利用されています。しかし、特定の商品カテゴリーがデータセットに十分に表現されていない可能性があり、不正確な分類につながります。
eBayは、Generative Adversarial Networks (GANs)を使用して、代表的でない商品カテゴリの合成画像を作成することで、この課題に取り組んだ。GANは有益であったが、Superb CurateのAuto-Curate機能のようなツールを取り入れることで、分類精度をさらに向上させることができます。Auto-Curateの'Curate What to Label'オプションは、不十分の商品カテゴリーを含む価値の高いデータを特定するのに役立ち、よりバランスの取れたデータセットを保証します。
"Find Edge Cases "機能は、希少な製品カテゴリーを特定するために使用でき、モデルの精度と多様性を向上さ せます。さらに、潜在的なラベリングエラーを特定し、"Find Mislabels "機能で修正することで、モデルの信頼性とパフォーマンスをさらに向上させることができます。"
従来のデータ補強技術
データの量と質の制限を克服するために、様々なデータ補強技術を適用することができます。これらの技術はデータの多様性を高め、モデルが様々なシナリオから学習できるようにします。ここでは、画像、テキスト、ビデオなど、さまざまなタイプのデータに対する一般的なデータ補強技術について詳しく説明します。
画像データの補強
画像データの補強は、機械学習における標準的な手順です。利用可能なデータのバリエーションを作成することで、モデルは異なる視点にさらされ、それによって汎化能力が向上します。以下に一般的なテクニックを紹介します:
1. 幾何学変換:
反転、回転、拡大縮小、トリミングは、データの多様性を高めるために使われる標準的なテクニックです。これらは、オブジェクトの本質的な特徴を維持しながら、その外観をわずかに変化させるという利点があります。
2. フォトメトリック変換:
明るさ、コントラスト、彩度を調整することで、データの多様性を大幅に高めることもできます。これらは、異なる照明条件に対応するモデルを準備する際に特に役立ちます。
3. ノイズインジェクション:
画像に人工的なノイズを加えることで、不完全な実世界のデータに対するモデルの耐性を高めることができます。

モデルの精度を向上させ、オーバーフィッティングを抑制するためのテキストデータ補強の例。
テキストデータの補強
テキストデータの補強は、テキストのセマンティクスを変更することなく、テキストのコンテキストを変更し、モデルの理解度を高め、オーバーフィッティングを減らすことを目的としています。よく使われる手法には以下のようなものがあります:
類義語の置き換え: この手法は、文章全体の意味を維持したまま、文章中の単語を類義語に置き換えるものです。
ランダム挿入: 文の文脈に合ったランダムな単語がランダムな位置に挿入されます。
ランダム削除: 文章からランダムに単語を取り除く
バックトランスレーション: テキストを別の言語に翻訳し、元の言語に翻訳し直すこと、 その際、文の構造に若干の変更が生じることが多い
ビデオデータの補強
ビデオデータの補強は、ビデオデータセットの多様性を高めるために使用されます。よく使われる方法には次のようなものがあります:
時間的転置: Tビデオフレームを異なる順序で並べ替え、多様性を作り出します。
フレーム除去: いくつかのフレームは、異なるシーケンスを作成するためにランダムに削除されます。
スピードの変更: ビデオの再生速度が変更され、速くなったり遅くなったりします。
空間の変換: 画像と同様に、幾何学的および測光変換をビデオデータに適用することができます。
データ補強のための高度なテクニック
上記の技術は広く使用されており、一般的に有効であるが、特定の例外的なケースでは不十分である可能性があります。それゆえ、生成逆説的ネットワーク(GAN)、メタ学習、ニューラル式転送、強化学習など、より高度な技術が、このような困難なシナリオに対処するために開発されてきました。
1. 生成的逆数ネットワーク (GANs):
GANは、実際のものとほとんど見分けがつかないような新しいデータインスタンスを生成することができます。例えば、GANは希少なクラスの画像をより多く作成するように訓練することができ、それによって希少性の問題を克服することができます。
さらに、GANは訓練データセットに新しいサンプルを生成することで、畳み込みニューラルネットワーク(CNN)の有効性を高めることができ、従来のデータ増強技術を上回る可能性があります。

Examples of traditional deep generative neural networks.
2.メタラーニング
メタ学習、または「学習するための学習」は、アルゴリズムが他の機械学習アルゴリズムから学習する機械学習の下位分野です。ディープラーニングの領域では、他のニューラルネットワークを介してニューラルネットワークを最適化することを指す。メタ学習は、ニューラルネットワークを訓練するための高レベルの要素を作成するために使用することができ、データ増強のためのユニークな利点を提供します。
3. ニュートラルスタイルの移行
このテクニックは、ディープラーニングを活用して、ある画像のスタイル(芸術的なスタイルなど)を別の画像に適用します。これにより、コア機能は同じでスタイルが異なる新しいデータインスタンスを作成することができます。ニューラル スタイル転送に基づく補強には、スタイルの決定、実行時間の遅さ、ストレージとメモリ容量の必要性の高さなどの課題が伴います。
4. 強化学習
強化学習(RL)は、エージェントが幅広いシナリオに対応できるように、拡張データで強化することができます。
RLベースの補強は、ある環境において、ある累積結果の評価を最大化するようにエージェントを訓練することです。データ補強によって様々なシナリオを提供することで、RLエージェントをよりロバストにし、新しい未知のシナリオに対応できるようにすることができます。
データ管理のための補強の自動化
データセットの質、多様性、バランスは、モデルの性能を決定する重要な要素です。膨大な量の多様なデータを収集するという固有の課題、特に稀なケースや頻度の低いケースについては、データ補強のような革新的な戦略を使用する必要があります。この手法は、既存のデータセットを強化することでモデルの学習能力を向上させ、モデルが学習するシナリオの幅を広げます。
しかし、重要な情報が変更されるリスク、再現性のないデータインスタンスの生成、根本的なデータの不均衡の管理、拡張データへのオーバーフィッティングの防止、計算コストや潜在的なバイアスへの対処など、データ拡張に課題がない訳ではありません。
SuperbのAIを搭載したソリューションであるCurateは、キュレーションプロセスを自動化するプラットフォームを提供することで、組織が効果的かつ効率的にデータを管理できるようにし、これらの課題を管理する上で重要な役割を果たします。Curateは、Auto-Curateのような技術を通じて、重要なデータポイントの特定とラベル付け、バランスの取れたデータセットの作成、外れ値や異常値の検出を支援します。
最終的に、機械学習プロジェクトの成功は、これらの技術やツールを慎重に適用し、モデルが高品質で多様かつバランスの取れたデータで学習され、実世界のアプリケーションで正確で信頼性の高い結果を出せるようにすることにかかっています。